


Caché de la CPU
Sabías ...
Esta selección wikipedia ha sido elegido por los voluntarios que ayudan Infantil SOS de Wikipedia para esta Selección Wikipedia para las escuelas. patrocinio SOS Niño es cool!
Una caché de CPU es un caché utilizada por la unidad central de procesamiento de un ordenador para reducir el tiempo medio para acceder la memoria. La memoria caché es una memoria más pequeño, más rápido que almacena copias de los datos de los más utilizados principales posiciones de memoria. Mientras la mayoría de los accesos de memoria se almacenan en caché posiciones de memoria, el promedio latencia de los accesos de memoria estará más cerca de la latencia de memoria caché que a la latencia de la memoria principal.
Visión de conjunto
Cuando el procesador necesita leer o escribir en una ubicación en la memoria principal, se comprueba primero si una copia de esos datos está en la caché. Si es así, el procesador lee inmediatamente o escribe en la caché, que es mucho más rápido que leer o escribir en la memoria principal.
La mayoría de las CPU de escritorio y servidores modernos tienen al menos tres cachés independientes: una caché de instrucciones para acelerar la instrucción ejecutable buscarme, una caché de datos para acelerar el acceso y almacenamiento de datos, y un buffer de traducción lookaside (TLB) utiliza para acelerar la traducción de direcciones de virtual a físico para ambas instrucciones ejecutables y datos. El caché de los datos se organizan por lo general como una jerarquía de más niveles de caché (L1, L2, etc .; ver cachés multinivel ).
Entradas de la caché
Los datos se transfieren entre la memoria y la memoria caché en bloques de tamaño fijo, llamadas líneas de caché. Cuando una línea de caché de la memoria se copia en la memoria caché, se crea una entrada de caché. La entrada de caché incluirá los datos copiados, así como la ubicación de la memoria solicitada (que ahora se llama una etiqueta).
Cuando el procesador necesita leer o escribir una ubicación en la memoria principal, en primer lugar comprueba para una entrada correspondiente en la memoria caché. Los controles de caché para el contenido de la posición de memoria solicitada en cualquier línea de caché que puedan contener esa dirección. Si el procesador encuentra que la posición de memoria está en la caché, se ha producido un movimiento de la memoria (de lo contrario, un error de caché). En el caso de:
- un acierto de caché, el procesador inmediatamente lee o escribe los datos en la línea de caché.
- un error de caché, la memoria caché asigna una nueva entrada, y las copias de los datos de la memoria principal. Entonces, la solicitud se cumple de los contenidos de la memoria caché.
El rendimiento de la caché
La proporción de accesos que dan como resultado un acierto de caché se conoce como la tasa de éxito, y puede ser una medida de la eficacia de la memoria caché para un programa o algoritmo dado.
Leer pierde retrasar la ejecución debido a que requieren datos a transferir desde la memoria mucho más lento que el propio caché. Área de escritura pueden ocurrir sin dicha pena, ya que el procesador puede continuar la ejecución mientras que los datos se copian en la memoria principal en el fondo.
Cachés de instrucciones son similares a los cachés de datos, pero la CPU sólo realiza accesos de lectura (instrucción obtiene) a la caché de instrucciones. (Con Arquitectura Harvard y CPUs arquitectura Harvard modificados, cachés de instrucciones y datos pueden ser separados para un mayor rendimiento, sino que también se pueden combinar para reducir la sobrecarga de hardware.)
Las políticas de sustitución
Con el fin de hacer espacio para la nueva entrada en un error de caché, la memoria caché puede tener que desalojar a una de las entradas existentes. La heurística que utiliza para seleccionar la entrada para desalojar se llama la política de reemplazo. El problema fundamental de cualquier política de reemplazo es que debe predecir qué entrada de caché existente es menos probable que se utilicen en el futuro. Predecir el futuro es difícil, así que no hay manera perfecta de elegir entre la variedad de políticas de reemplazo disponibles.
Una política de sustitución popular, menos usado recientemente (LRU), sustituye la entrada menos recientemente visitada.
Marcado algunos intervalos de memoria como no almacenable en caché puede mejorar el rendimiento, evitando el almacenamiento en caché de las regiones de memoria que están raramente volver a acceder. Esto evita la sobrecarga de cargar algo en la memoria caché, sin tener ninguna reutilización.
- Entradas de caché también se pueden desactivar o bloqueado en función del contexto.
Políticas de escritura
Si los datos se escriben en la memoria caché, en algún momento también debe ser escrito a la memoria principal. El momento de esta escritura se conoce como la política de escritura.
- En un escribir a través de caché, cada escritura a la memoria caché hace una escritura en la memoria principal.
- Alternativamente, en una write-back o caché copia-back, las escrituras no son inmediatamente reflejados en la memoria principal. En cambio, el caché rastrea qué ubicaciones se han escrito más de (estos lugares están marcados sucio). Los datos de estos lugares se escriben de nuevo a la memoria principal sólo cuando esos datos se desaloja de la memoria caché. Por esta razón, un fallo de lectura en una memoria caché de escritura no puede a veces requerir de dos accesos a memoria de servicio: uno para escribir primero el lugar sucio en la memoria y luego otro para leer la nueva ubicación de la memoria.
Hay políticas intermedios. La caché puede ser escribir a través, pero las escrituras puede ser celebrada en una cola de almacenar datos temporalmente, por lo general de manera que varias tiendas se pueden procesar juntos (lo que puede reducir plazos de entrega de autobuses y mejorar la utilización de autobuses).
Los datos de la principal que es almacenada en caché de memoria pueden ser cambiadas por otras entidades (por ejemplo, el uso de periféricos Acceso directo a la memoria o el procesador multi-core), en cuyo caso la copia en la caché pueden llegar a ser fuera de fecha o rancio. Alternativamente, cuando la CPU en un procesador multi-núcleo actualiza los datos en la caché, copias de los datos en las memorias caché asociados con otros núcleos se convertirán en rancio. Los protocolos de comunicación entre los gerentes de caché que mantienen los datos coherentes se conocen como protocolos de coherencia de caché.
Puestos de CPU
El tiempo necesario para buscar a una línea de caché de la memoria (leer latencia) asuntos porque la CPU se quedará sin cosas que hacer mientras se espera la línea de caché. Cuando una CPU alcanza este estado, se le llama un puesto.
Como CPUs son más rápidos, puestos debido a la caché pierde desplazan más potencial de cálculo; CPUs modernas pueden ejecutar cientos de instrucciones en el tiempo necesario para buscar una sola línea de caché de la memoria principal. Diversas técnicas se han empleado para mantener la CPU ocupado durante este tiempo.
- Fuera de la orden CPU (Pentium Pro y posteriormente diseños de Intel, por ejemplo) intento de ejecutar las instrucciones independientes después de la instrucción que se espera de los datos de fallos de cache.
- Otra tecnología, utilizada por muchos procesadores, es multithreading simultáneo (SMT), o - en la terminología de Intel - Hyper-Threading (HT), que permite a un hilo alternativo para utilizar la base de la CPU mientras que un primer hilo espera que los datos provienen de la memoria principal.
Estructura de entrada de caché
Entradas de fila de caché por lo general tienen la siguiente estructura:
| etiqueta | bloque de datos | bits de la bandera |
El bloque de datos (línea de caché) contiene los datos reales se captan desde la memoria principal. La etiqueta contiene (parte de) la dirección de los datos reales se captan desde la memoria principal. Los bits de la bandera se discuten a continuación.
El "tamaño" de la memoria caché es la cantidad de datos de la memoria principal que puede contener. Este tamaño puede calcularse como el número de bytes almacenados en cada bloque de datos veces el número de bloques almacenados en la memoria caché. (El número de bits de la variable y el indicador es irrelevante para este cálculo, aunque sí afecta el área física de una memoria caché).
Una dirección de memoria efectiva se divide ( MSB a LSB) en la etiqueta, el índice y el desplazamiento de bloque.
| etiqueta | índice | bloque de desplazamiento |
El índice describe qué fila caché (que línea de caché) que los datos se ha puesto en. La longitud índice es 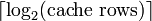 Bits. El desplazamiento del bloque especifica los datos que desee dentro del bloque de datos almacenados dentro de la fila caché. Normalmente la dirección eficaz es en bytes, por lo que el desplazamiento de bloque de longitud es
Bits. El desplazamiento del bloque especifica los datos que desee dentro del bloque de datos almacenados dentro de la fila caché. Normalmente la dirección eficaz es en bytes, por lo que el desplazamiento de bloque de longitud es 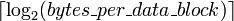 Bits. La etiqueta contiene los bits más significativos de la dirección, lo que se compara con la fila actual (la fila ha sido recuperada por índice) para ver si es la que necesitamos u otra posición de memoria irrelevante que pasó a tener los mismos bits de índice como el que queremos. La etiqueta de longitud en bits es
Bits. La etiqueta contiene los bits más significativos de la dirección, lo que se compara con la fila actual (la fila ha sido recuperada por índice) para ver si es la que necesitamos u otra posición de memoria irrelevante que pasó a tener los mismos bits de índice como el que queremos. La etiqueta de longitud en bits es 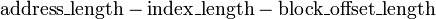 .
.
Algunos autores se refieren a la compensación como simplemente el "desplazamiento" o el "desplazamiento" del bloque.
Ejemplo
El Pentium 4 original tenía un 4 vías establecer caché asociativa datos L1 de tamaño 8 KB con bloques de caché de 64 bytes. Por lo tanto, hay 8 KB / 64 = 128 bloques de caché. Si es asociativa por conjuntos de 4 vías, esto implica 128/4 = 32 conjuntos (y por lo tanto 2 ^ 5 = 32 diferentes índices). Hay 64 = 2 ^ 6 posibles compensaciones. Desde la dirección de CPU es de 32 bits, esto implica 32 = 21 + 5 + 6, y por lo tanto, 21 bits de campo de la etiqueta. El Pentium 4 original también tenía un 8 vías establecer asociativo L2 caché integrada de tamaño de 256 KB con 128 bloques de caché de bytes. Esto implica 32 = 17 + 8 + 7, y por lo tanto, 17 bits de campo de etiqueta.
Bits de la bandera
Una caché de instrucciones requiere sólo un bit de bandera por entrada fila caché: un poco válida. El bit de validez indica si un bloque de caché se ha cargado con datos válidos.
En el arranque, el hardware establece todos los bits válidos en todos los cachés a "no válido". Algunos sistemas también establecen un poco válido "no válido" en otras ocasiones, como cuando varios maestros bus espionaje hardware en la memoria caché de un procesador oye una dirección de difusión de algún otro procesador, y se da cuenta de que ciertos bloques de datos en la caché local ahora son obsoletos y deben ser marcados como no válidos.
Una caché de datos normalmente requiere dos bits de la bandera por entrada fila caché: un poco válido y también una poco sucio. El poco sucio indica si ese bloque no ha cambiado desde que se lee desde la memoria principal - "limpia", o si el procesador ha escrito datos en ese bloque (y el nuevo valor no ha hecho todo el camino a la memoria principal) - "sucio".
Asociatividad
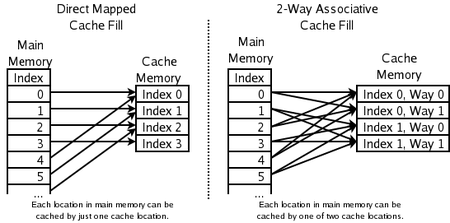
La política de sustitución decide donde en la caché una copia de una entrada en particular de la memoria principal se irá. Si la política de reemplazo es libre de elegir cualquier entrada en la caché para mantener la copia, la caché se llama completamente asociativo. En el otro extremo, si cada entrada en la memoria principal puede ir en un solo lugar en la memoria caché, la memoria caché es directa asignada. Muchos cachés implementan un compromiso en el que cada entrada en la memoria principal puede ir a cualquiera de los lugares de N en la memoria caché, y se describen como conjunto de N vías asociativas. Por ejemplo, la caché de datos de nivel 1 en una AMD Athlon es de 2 vías establecer asociativo, lo que significa que cualquier lugar en particular en la memoria principal puede almacenar en caché en cualquiera de las 2 localidades de la caché de datos de nivel 1.
La asociatividad es un compensación. Si hay diez lugares a los que la política de reemplazo podría haber asignado una ubicación de la memoria, a continuación, para comprobar si ese lugar está en la caché, diez entradas de caché deben ser buscados. Comprobación de más lugares toma más poder, área de chip, y potencialmente el tiempo. Por otro lado, cachés con más asociatividad sufren menos área (véase área de conflicto, a continuación), por lo que los desechos de CPU menos el tiempo de lectura de la memoria principal lento. La regla general es que la duplicación de la asociatividad, de asignación directa de 2 vías, o de 2 vías para 4 vías, tiene casi el mismo efecto sobre la tasa de aciertos como duplicar el tamaño de la caché. Aumenta Asociatividad más allá de 4 vías tienen mucho menos efecto sobre la tasa de aciertos, y por lo general se hacen por otras razones (ver aliasing virtual, a continuación).
Con el fin de peor pero simple para mejor, pero compleja:
- caché asignada directa - Los mejores (más rápido) hit veces, y lo que la mejor solución de compromiso para cachés "grandes"
- 2 vías establecer caché asociativa
- 2 vías caché asociativa sesgada - El mejor compromiso para cachés cuyos tamaños están en el rango de 4 K-8K bytes.
- 4 vías establecer caché asociativa
- caché totalmente asociativa - los mejores (más bajos) las tasas de la falta, y lo que la mejor solución de compromiso cuando el penalti fallado es muy alta
Caché de correlación directa
Aquí cada ubicación en la memoria principal sólo puede ir en una entrada en la caché. No tiene una política de reemplazo como tal, ya que no hay opción de que el contenido de la entrada de caché para desalojar. Esto significa que si dos lugares se asignan a la misma entrada, pueden golpear continuamente el uno al otro. Aunque simple, una caché de correlación directa tiene que ser mucho más grande que un uno asociativo para dar un rendimiento comparable, y es más impredecible.
2 vías establecer caché asociativa
Si cada ubicación en la memoria principal puede almacenar en caché en cualquiera de las dos ubicaciones en la memoria caché, una pregunta lógica es: ¿cuál de los dos El esquema más simple y más utilizado, se muestra en el diagrama de la derecha arriba, es el uso de la bits menos significativos de índice de la posición de memoria que el índice de la memoria caché, y que tienen dos entradas para cada índice. Una ventaja de este esquema es que las etiquetas almacenados en la caché no tienen que incluir la parte de la dirección de memoria principal, que está implícita en el índice de la memoria caché. Dado que las etiquetas de caché tienen menos bits, toman menos área en el chip microprocesador y se pueden leer y comparación más rápido. También LRU es especialmente sencillo, ya que sólo un bit necesita ser almacenada para cada par.
La ejecución especulativa
Una de las ventajas de una caché de mapeado directo es que permite simple y rápido especulación. Una vez que la dirección se ha calculado, se conoce el índice de una caché que podría tener una copia de esa ubicación en la memoria. Esa entrada de caché se puede leer, y el procesador puede seguir trabajando con esos datos antes de que finalice la comprobación de que la etiqueta de hecho coincide con la dirección solicitada.
La idea de tener el procesador utiliza los datos almacenados en caché antes de que se complete el fósforo de etiqueta se puede aplicar a asociativos cachés también. Un subconjunto de la etiqueta, llamada una pista, se puede utilizar para escoger sólo una de las posibles entradas de la caché de mapeo a la dirección solicitada. La entrada seleccionada por la pista se puede utilizar en paralelo con la comprobación de la etiqueta completa. La técnica indirecta funciona mejor cuando se usa en el contexto de la traducción de direcciones, como se explica a continuación.
2 vías caché asociativa sesgada
Otros esquemas se han sugerido, como la memoria caché sesgada, donde el índice 0 para modo directo es, como anteriormente, pero el índice de forma 1 se forma con una función hash. Una buena función hash tiene la propiedad de que se ocupa de que conflicto con la asignación directa no tiende a conflicto cuando mapeado con la función hash, y lo que es menos probable que un programa va a sufrir de un número inesperadamente grande de conflicto se pierde debido a un acceso patológica patrón. La desventaja es la latencia adicional de cálculo de la función hash. Además, cuando llega el momento de cargar una nueva línea y desalojar a una vieja línea, puede ser difícil determinar qué línea existente se utilizó menos recientemente, debido a que los nuevos conflictos de línea con datos a diferentes índices en cada sentido; Seguimiento LRU para cachés no asimétricos se hace generalmente sobre una base per-set. Sin embargo, cachés asimétricos asociativo tienen importantes ventajas sobre los de asociación de conjuntos convencionales.
Cache-Pseudo asociativo
Un verdadero caché asociativa en conjunto pone a prueba todas las formas posibles de forma simultánea, usando algo como un memoria de contenido direccionable. Una caché asociativa pseudo-prueba cada forma posible de una en una. Una caché hash refrito y un cache-columna asociativa son ejemplos de caché pseudo-asociativa.
En el caso común de encontrar en un éxito en la primera forma probada, una caché de pseudo-asociativa es tan rápido como un caché de correlación directa. Pero tiene una tasa de fallos conflicto mucho más bajo que un caché de asignación directa, más cercana a la tasa de fallos de un caché totalmente asociativa.
Caché pierdas
Un error de caché se refiere a un fallido intento de leer o escribir en una hoja de datos en la caché, lo que se traduce en un acceso a la memoria principal con una latencia mucho más tiempo. Hay tres tipos de fallos de caché: instrucción leer señorita, la lectura de datos de la falta, y escritura de datos señorita.
Una caché de lectura señorita de una caché de instrucciones generalmente causa la mayor retardo, porque el procesador, o al menos la hilo de ejecución, tiene que esperar (parada) hasta que la instrucción se descargue de la memoria principal.
Una caché de lectura se pierda de una caché de datos por lo general causa menos retraso, porque las instrucciones no dependientes de la lectura de caché pueden ser emitidos y continúan la ejecución hasta que se devuelvan los datos de la memoria principal, y las instrucciones dependientes puede reanudar la ejecución.
Un error de caché de escritura a una caché de datos generalmente causa el menor retraso, porque la escritura puede ponerse en cola y hay pocas limitaciones en la ejecución de las instrucciones siguientes. El procesador puede continuar hasta que la cola está llena.
Con el fin de reducir la tasa de error de caché, una gran cantidad de análisis se ha realizado sobre el comportamiento de caché en un intento de encontrar la mejor combinación de tamaño, asociatividad, tamaño de bloque, y así sucesivamente. Secuencias de referencias a memoria realizadas por los programas de referencia se guardan como rastros de direcciones. Análisis posteriores simulan variados diseños posible caché en estas trazas de direcciones largas. Dar sentido a cómo las muchas variables afectan la tasa de aciertos de caché puede ser bastante confuso. Una importante contribución a este análisis fue hecho por Mark Hill, que se separó pierde en tres categorías (conocida como las Tres Cs):
- Pierde obligatorios son aquellos fallos causados por la primera referencia a una ubicación en la memoria. Tamaño de caché y asociatividad no hacen ninguna diferencia en el número de fallos obligatorios. La captura previa puede ayudar aquí, como los tamaños de bloque más grande de caché puede (que son una forma de obtención previa). Pierde obligatorios se denominan misses como frías a veces.
- Pierde capacidad son aquellos accidentes que se producen independientemente de la asociatividad o tamaño de bloque, únicamente debido al tamaño finito de la memoria caché. La curva de la tasa de fallos de capacidad frente a tamaño de la caché da una medida de la localidad temporal de una corriente de referencia particular. Tenga en cuenta que no existe la noción útil de una memoria caché de ser "completa" o "vacío" o "capacidad de cerca": cachés de CPU casi siempre tienen casi cada línea de llenado de una copia de alguna línea en la memoria principal, y casi cada asignación de un nuevo línea requiere el desalojo de una antigua línea.
- Área de conflicto son los accidentes que podrían haberse evitado, habían desalojado la caché no una entrada anterior. Área de conflicto pueden desglosar en área de cartografía, que son inevitables dada una determinada cantidad de asociatividad, y echa de recambio, que se deben a la elección víctima en particular de la política de reemplazo.
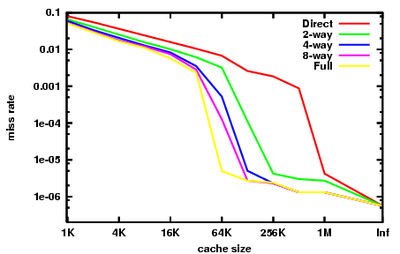
La gráfica de la derecha resume el rendimiento de la caché se ve en la parte entera de los puntos de referencia SPEC CPU2000, procedentes de la colina y Cantin. Estos puntos de referencia pretenden representar el tipo de carga de trabajo que una estación de trabajo de ingeniería podría ver en un día determinado. El lector debe tener en cuenta que la búsqueda de puntos de referencia que son incluso útilmente representante de muchos programas ha sido muy difícil, y siempre habrá importantes programas con un comportamiento muy diferente a lo que se muestra aquí.
Podemos ver los diferentes efectos de las tres C en este gráfico.
En la extrema derecha, con el tamaño de la memoria caché con la etiqueta "Inf", tenemos area obligatorias. Si queremos mejorar el rendimiento de una máquina en SPECint2000, aumentando el tamaño de caché más allá de 1 MB es esencialmente inútil. Esa es la visión dada por los fallos obligatorios.
La tasa de error de caché totalmente asociativa aquí es casi representante de la tasa de fallos de capacidad. La diferencia es que los datos presentados es a partir de simulaciones suponiendo una Política de reemplazo LRU. Mostrando la tasa de fallos de capacidad requeriría un política de reemplazo perfecto, es decir, un oráculo que mira hacia el futuro para encontrar una entrada de caché que en realidad no va a ser golpeado.
Tenga en cuenta que nuestra aproximación de la tasa de fallos de capacidad cae abruptamente entre 32 kB y 64 kB. Esto indica que el punto de referencia tiene una conjunto de trabajo de aproximadamente 64 kB. Un diseñador de caché CPU examinar este punto de referencia tendrá un fuerte incentivo para ajustar el tamaño de la caché de 64 kB en lugar de 32 kB. Tenga en cuenta que, en este punto de referencia, ninguna cantidad de asociatividad puede hacer una caché de 32 kB realizar, así como un 64 kB de 4 vías, o incluso un 128 KB de caché de asignación directa.
Por último, tenga en cuenta que entre el 64 kB y 1 MB hay una gran diferencia entre cachés de asignación directa y completamente asociativas. Esta diferencia es la tasa de fallos de conflictos. La idea de mirar a las tasas se pierda de conflicto es que las memorias caché secundaria se benefician mucho de alta asociatividad.
Este beneficio era bien conocido en los años 80 y principios de los 90, cuando los diseñadores de CPU no podían caber grandes alijos en el chip, y no podía obtener suficiente ancho de banda ni a la memoria caché de datos o en la memoria caché de etiqueta para implementar alta asociatividad en cachés off-chip . Se intentaron hacks Desesperadas: el MIPS R8000 utiliza caro fuera del chip etiqueta dedicada SRAM, que se habían incrustado comparadores etiqueta y grandes conductores en las líneas de los partidos, con el fin de implementar un 4 MB de 4 vías caché asociativa. El MIPS R10000 utiliza chips de SRAM ordinarios para las etiquetas. Acceso Tag para ambos sentidos tomó dos ciclos. Para reducir la latencia, el R10000 adivinaría que camino de la caché golpearía en cada acceso.
Traducción de direcciones
La mayoría de las CPU de propósito general implementar alguna forma de memoria virtual. En resumen, cada programa que se ejecuta en la máquina ve su propia simplificado espacio de direcciones, la cual contiene el código y los datos sólo para ese programa. Cada programa utiliza este espacio de direcciones virtuales sin tener en cuenta donde existe en la memoria física.
La memoria virtual requiere el procesador para traducir direcciones virtuales generados por el programa en direcciones físicas en la memoria principal. La porción del procesador que no esta traducción se conoce como el unidad de manejo de memoria (MMU). La vía rápida a través de la MMU puede realizar esas traducciones almacenados en la tampón de traducción lookaside (TLB), que es una memoria caché de asignaciones desde el sistema operativo de tabla de páginas.
Para los propósitos de la presente discusión, hay tres características importantes de la traducción de direcciones:
- Latencia: La dirección física está disponible en la MMU algún tiempo, quizás unos pocos ciclos, después de la dirección virtual está disponible desde el generador de direcciones.
- Aliasing: direcciones virtuales múltiples pueden asignar a una sola dirección física. La mayoría de los procesadores de garantizar que todos los cambios a que la dirección física única sucederán en el orden del programa. Para cumplir con esa garantía, el procesador debe asegurarse de que sólo una copia de una dirección física reside en la memoria caché en un momento dado.
- Granularidad: El espacio de direcciones virtuales se divide en páginas. Por ejemplo, un 4 GB de espacio de direcciones virtuales podría ser cortado en 1.048.576 páginas de tamaño 4 kB, cada una de las cuales se pueden asignar de forma independiente. Puede haber múltiples tamaños de página admitidos; ver memoria virtual para la elaboración.
Una nota histórica: algunos sistemas de memoria virtual primeros eran muy lento, debido a que requieren un acceso a la tabla de páginas (que tuvo lugar en la memoria principal) antes de cada acceso programado a la memoria principal. Sin cachés, este corte eficazmente la velocidad de la máquina en medio. El primer caché de hardware que se utiliza en un sistema informático no era en realidad una caché de datos o instrucción, sino más bien una TLB.
Cachés pueden ser divididos en 4 tipos, en función de si el índice o tag corresponden a las direcciones físicas o virtuales:
- Físicamente indexada, etiquetados físicamente (Pipt) cachés utilizan la dirección física tanto para el índice y la etiqueta. Si bien esto es simple y evita problemas con aliasing, también es lento, como la dirección física debe ser buscado (que podría implicar un fallo TLB y el acceso a la memoria principal) antes de que la dirección se puede consultar en la caché.
- Prácticamente indexada, prácticamente etiquetados (VIVT) cachés utilizan la dirección virtual tanto para el índice y la etiqueta. Este esquema de almacenamiento en caché puede resultar en operaciones de búsqueda mucho más rápido, ya que la MMU no necesita ser consultado primero para determinar la dirección física de una dirección virtual dado. Sin embargo, VIVT sufre de problemas de solapamiento, donde varias direcciones virtuales diferentes pueden hacer referencia a la misma dirección física. El resultado es que dichas direcciones se almacenan en caché por separado a pesar de referirse a la misma memoria, causando problemas de coherencia. Otro problema es homónimos, donde la misma dirección virtual se asigna a varias direcciones físicas diferentes. No es posible distinguir estas asignaciones con sólo mirar el índice virtual, aunque soluciones potenciales incluyen: vaciar la caché después de una cambio de contexto, obligando a los espacios de direcciones a ser que no se solapan, etiquetar la dirección virtual con un ID de espacio de direcciones (ASID), o el uso de etiquetas físicas. Además, hay un problema que de virtual a físico asignaciones pueden cambiar, por lo que requeriría lavado líneas de caché, como el AV ya no sería válida.
- Etiquetados físicamente (VIPT) cachés Prácticamente indexado, use la dirección virtual para el índice y la dirección física en la etiqueta. La ventaja sobre Pipt es menor latencia, como la línea de caché se puede consultar en paralelo con la traducción TLB, sin embargo, la etiqueta no se puede comparar hasta que la dirección física está disponible. La ventaja sobre VIVT es que desde la etiqueta tiene la dirección física, la memoria caché puede detectar homónimos. VIPT requiere más bits de la variable, como los bits de índice ya no representan a la misma dirección.
- Físicamente indexada, prácticamente etiquetados (TV-IAM) cachés son sólo teóricas, ya que sería básicamente inútil.
La velocidad de esta recurrencia (la latencia de carga) es crucial para el rendimiento de la CPU, y así más modernas nivel-1 cachés están prácticamente indexado, que al menos permite TLB de búsqueda de la MMU de proceder en paralelo con ir a buscar los datos de la RAM caché.
Pero indexación virtual no es la mejor opción para todos los niveles de caché. El costo de tratar con alias virtuales crece con el tamaño de la memoria caché, y como resultado la mayoría de nivel-2 y más grandes cachés están indexados físicamente.
Cachés han utilizado históricamente ambas direcciones virtuales y físicas para las etiquetas de caché, aunque marcado virtual es ahora poco común. Si la búsqueda de TLB puede terminar antes de la búsqueda de RAM caché, entonces la dirección física está disponible en el tiempo para la etiqueta comparar, y no hay necesidad de etiquetado virtual. Las grandes alijos, entonces, tienden a ser etiquetados físicamente, y sólo pequeños cachés muy baja latencia son prácticamente etiquetados. En las CPUs de propósito general recientes, etiquetado virtual ha sido sustituida por vhints, como se describe a continuación.
Problemas homónimos y sinónimos
El caché que se basa en la indexación virtual y el etiquetado se vuelve incoherente después de la misma dirección virtual se hace corresponder a diferentes direcciones físicas ( homónimo). Esto se puede resolver mediante el uso de la dirección física para el marcado o mediante el almacenamiento de la ID de espacio de direcciones en la línea de caché. Sin embargo, el último de estos dos enfoques no ayuda en contra de la Sinónimo problema, donde varias líneas de caché terminan el almacenamiento de datos para la misma dirección física. Escribiendo a un determinado lugar puede actualizar sólo una ubicación en la memoria caché, dejando a los demás con datos inconsistentes. Este problema podría resolverse mediante el uso de diseños de memoria no se superponen para diferentes espacios de direcciones o de lo contrario los de caché (o parte de ella) debe limpiarse, cuando los cambios de asignación.
Etiquetas virtuales y vhints
La gran ventaja de las etiquetas virtuales es que, para cachés asociativas, que permiten la lucha en parejas para proceder antes de lo virtual a la traducción físico está hecho. Sin embargo,
- sondas de coherencia y desalojos presentan una dirección física para la acción. El hardware debe tener algún medio de la conversión de las direcciones físicas en un índice de caché, por lo general mediante el almacenamiento de etiquetas físicas, así como etiquetas virtuales. En comparación, un caché físicamente etiquetado no necesita para mantener las etiquetas virtuales, lo que es más simple.
- Cuando un virtual para la cartografía física se elimina de la TLB, entradas de caché con las direcciones virtuales tendrán que ser tiraba alguna manera. Alternativamente, si las entradas de caché se permiten en las páginas que no se asignaron por el TLB, entonces esas entradas tendrán que ser tiraba cuando los derechos de acceso en esas páginas se cambian en la tabla de páginas.
También es posible para el sistema operativo para asegurarse de que no hay alias virtuales son simultáneamente residente en la memoria caché. El sistema operativo hace que esta garantía mediante la aplicación de la página para colorear, que se describe a continuación. Algunos procesadores RISC tempranas (SPARC, RS / 6000) tomaron este enfoque. No se ha utilizado recientemente, como el costo de hardware de detección y el desalojo de los alias virtuales ha caído y la complejidad del software y la penalización de rendimiento de página para colorear perfecto ha resucitado.
Puede ser útil para distinguir las dos funciones de etiquetas en una memoria caché asociativa: se utilizan para determinar qué camino de la entrada de conjunto para seleccionar, y se utilizan para determinar si la memoria caché ha golpeado o perder. La segunda función debe ser siempre correcta, pero es permisible para la primera función de adivinar, y obtener la respuesta equivocada de vez en cuando.
Algunos procesadores (por ejemplo primeros SPARCS) tienen cachés con ambas etiquetas virtuales y físicos. Las etiquetas virtuales se utilizan para la selección de camino, y las etiquetas físicas se utilizan para determinar impredecible. Este tipo de memoria caché goza de la ventaja de latencia de una caché prácticamente etiquetado, y la interfaz de software simple de un caché físicamente etiquetado. Lleva el coste añadido de etiquetas duplicadas, sin embargo. También, durante el procesamiento de la falta, las formas alternativas de la línea de caché indexada tienen que ser sondeado para los alias virtuales y cualquier coincidencia desalojadas.
El área adicional (y un poco de latencia) pueden mitigarse manteniendo consejos virtuales con cada entrada de caché en vez de etiquetas virtuales. Estas sugerencias son un subconjunto o hash de la etiqueta virtual, y se utilizan para la selección de la forma de la memoria caché de la que para obtener datos y una etiqueta física. Al igual que un caché prácticamente etiquetado, puede haber un partido pista pero desajuste etiqueta física virtual, en cuyo caso la entrada de la caché con la indirecta correspondiente debe ser desalojado para que cache accede después de la caché de llenar en esta dirección tendrá sólo un partido pista. Desde consejos virtuales tienen menos bits que etiquetas virtuales que distinguen a unos de otros, un caché prácticamente insinuado sufre más fallos de conflicto que una memoria caché prácticamente etiquetado.
Tal vez una reducción de las pistas virtuales se puede encontrar en los Pentium 4 (núcleos de Willamette y de Northwood). En estos procesadores de la pista virtual es eficaz 2 bits, y la caché es asociativa por conjuntos de 4 vías. Efectivamente, el hardware mantiene una permutación sencilla de direcciones virtuales para indexar caché, por lo que no es necesario contenido direccionable memoria (CAM) para seleccionar la derecha una de las cuatro formas descabellada.
Página para colorear
Las grandes cachés físicamente indexados (generalmente cachés secundarios) se ejecutan en un problema: el sistema operativo en lugar de los controles de aplicación que las páginas chocan unos con otros en la caché. Las diferencias en la asignación de página de un programa dirigido a la siguiente ventaja a las diferencias en los patrones de colisión caché, lo que puede dar lugar a grandes diferencias en el desempeño del programa. Estas diferencias pueden hacer que sea muy difícil conseguir un tiempo consistente y repetible para una ejecución de referencia.
Para entender el problema, considere una CPU con 1 MB de caché físicamente indexado de asignación directa de nivel 2 y 4 kB páginas de memoria virtual. Páginas físicas secuenciales se asignan a ubicaciones secuenciales en la memoria caché hasta después de 256 páginas el patrón envuelve. Podemos etiquetar cada página física con un color de 0 a 255 para indicar en qué parte del caché que puede ir. Ubicaciones dentro de las páginas físicas con diferentes colores que no pueden entrar en conflicto en la caché.
Un programador de intentar hacer el máximo uso de la caché de la facultad de convenir la forma de acceso de su programa de manera que sólo 1 MB de datos necesitan ser almacenados en caché en un momento dado, evitando de esta manera pierde capacidad. Pero también debe asegurarse de que los patrones de acceso no tienen fallos de conflicto. Una manera de pensar acerca de este problema es dividir las páginas virtuales utiliza el programa y asignarles colores virtuales de la misma manera como se asignan los colores físicos a páginas físicas antes. El programador puede entonces ordenar los patrones de acceso de su código de modo que no hay dos páginas con el mismo virtual de color están en uso al mismo tiempo. Existe una amplia literatura sobre dichas optimizaciones (por ejemplo, bucle de optimización nido), procedente en gran parte de la Computación de Alto Rendimiento (HPC) de la comunidad.
El problema es que mientras que todos los páginas en uso en cualquier momento dado pueden tener diferentes colores virtuales, algunos pueden tener los mismos colores físicas.De hecho, si el sistema operativo asigna páginas físicas a las páginas virtuales al azar y de manera uniforme, es extremadamente probable que algunas páginas tendrán el mismo color físico y, a continuación poblaciones de esas páginas chocarán en la memoria caché (esta es laparadoja del cumpleaños).
La solución es tener el intento del sistema operativo para asignar diferentes páginas en color física a diferentes colores virtuales, una técnica llamada página para colorear . Aunque la asignación real de lo virtual a color físico es irrelevante para el rendimiento del sistema, las asignaciones impares son difíciles de perder de vista y tener pocos beneficios, por lo que la mayoría se acerca a la página para colorear, simplemente tratar de mantener los colores de página físicos y virtuales de la misma.
Si el sistema operativo puede garantizar que cada uno de los mapas físicos de página para un solo color virtual, entonces no hay alias virtuales, y el procesador pueden utilizar cachés prácticamente indexadas sin necesidad de sondas de alias virtuales adicionales durante la manipulación señorita. Alternativamente, el O / S puede eliminar una página de la caché cada vez que cambia de un color virtual a otro. Como se mencionó anteriormente, se utilizó este enfoque para algunos SPARC temprano y RS / 6000 diseños.
Jerarquía de caché en un procesador moderno
Los procesadores modernos tienen múltiples cachés que interactúan en el chip.
El funcionamiento de una memoria caché en particular puede ser completamente especificada por:
- el tamaño de la caché
- el tamaño de bloque de caché
- el número de bloques en un conjunto
- la caché de fijar la política de sustitución
- la política de caché de escritura (write-through o write-back)
Si bien todos los bloques de caché en un caché particular, son del mismo tamaño y tienen la misma asociatividad, típicamente cachés "de bajo nivel" (como la memoria caché L1) tienen un tamaño más pequeño, tienen bloques más pequeños, y tienen menos bloques en un conjunto , mientras que "cachés de nivel superior" (como la memoria caché L3) tienen más de gran tamaño, los bloques más grandes, y más bloques en un conjunto.
Cachés Especializados
Memoria de acceso CPUs Pipelined desde múltiples puntos de la tubería: extracción de instrucción, la traducción de direcciones de virtual a físico y de recuperación de datos (ver tubería clásico RISC). El diseño natural es utilizar diferentes cachés físicos para cada uno de estos puntos, de modo que nadie recurso físico tiene que ser programado para dar servicio a dos puntos de la tubería. Por lo tanto, naturalmente, la tubería termina con al menos tres cachés separadas (instrucción, TLB, y datos), cada uno especializado para su función particular.
Tuberías con instrucciones y datos cachés separadas, ahora predominantes, se dice que tiene una arquitectura de Harvard. Originalmente, esta frase se refiere a las máquinas con instrucciones y datos memorias separadas, que no resultaron del todo popular. La mayoría de los CPU modernos tienen una sola memoria arquitectura von Neumann.
Caché Víctima
Un caché víctima es una memoria caché se utiliza para mantener los bloques desalojadas de un caché de la CPU al reemplazo. La caché víctima se encuentra entre el caché principal y su ruta de recarga, y sólo tiene bloques que fueron desalojados de la caché principal. La caché víctima suele ser totalmente asociativa, y está destinado a reducir el número de fallos de conflicto. Muchos programas de uso común no requieren un mapeo asociativo para todos los accesos. De hecho, sólo una pequeña fracción de la accesos a memoria del programa requieren alta asociatividad. La caché víctima explota esta propiedad, proporcionando alta asociatividad sólo a estos accesos. Fue introducido por Norman Jouppi de diciembre de 1990.
Caché de seguimiento
Uno de los ejemplos más extremos de la especialización de caché es la memoria caché rastro encontrado en los Intel Pentium 4 microprocesadores. Un caché traza es un mecanismo para aumentar la instrucción buscar a ancho de banda y consumo de energía decreciente (en el caso de la Pentium 4) mediante el almacenamiento de los rastros de instrucciones que ya han sido extraídas y decodificados.
La publicación académica ampliamente reconocido más temprano de caché rastro era porEric Rotenberg,Steve Bennett, yJim Smith en su artículo 1996"Trace caché: un Enfoque de baja latencia a mayor ancho de banda que trae la Instrucción".
Una publicación anterior es la patente estadounidense 5.381.533, "la memoria caché de instrucciones flujo dinámico organizado en torno a segmentos independientes traza de la línea de dirección virtual", deAlex Peleg yUri Weiser de Intel Corp., patente presentada el 30 de marzo de 1994, una continuación de una solicitud presentada en 1992, más tarde abandonado.
Un caché almacena rastro instrucciones ya sea después de que han sido decodificadas, o como se les retiró. Generalmente, se añaden instrucciones para rastrear cachés en grupos que representan, ya sea individuales bloques básicos o rastros de instrucciones dinámicas. Una traza dinámica ("camino rastro") contiene sólo instrucciones cuyos resultados se utilizan en realidad, y elimina las instrucciones siguientes ramas tomadas (ya que no se ejecutan); una traza dinámica puede ser una concatenación de varios bloques básicos. Esto permite que la unidad de recuperación de instrucciones de un procesador a buscar a varios bloques básicos, sin tener que preocuparse de sucursales en el flujo de ejecución.
Traza líneas se almacenan en la memoria caché de rastreo basado en el contador de programa de la primera instrucción en la traza y un conjunto de predicciones sucursales. Esto permite almacenar distintos caminos traza que se inician en la misma dirección, cada una representando diferentes resultados sucursales. En la extracción de instrucción etapa de una tubería, el contador de programa actual junto con un conjunto de predicciones de sucursales está marcada en la memoria caché de rastreo para un golpe. Si hay un golpe, una línea de trazo se suministra a buscar lo que no tiene que ir a una caché regular o en la memoria de estas instrucciones. La caché traza continúa alimentando la unidad de fetch hasta que termine la línea de seguimiento o hasta que haya una predicción errónea en la tubería. Si hay un fallo, una nueva traza comienza a construirse.
Traza cachés también se utilizan en procesadores como elIntel Pentium 4 para almacenar micro-operaciones ya decodificados, o traducciones de instrucciones x86 complejas, de modo que la próxima vez que se necesita una instrucción, no tiene que ser decodificada de nuevo.
Cachés multinivel
Otra cuestión es el equilibrio fundamental entre la latencia de la memoria caché y tasa de éxito. Cachés más grandes tienen mejores tasas de éxito, pero la latencia más largo. Para hacer frente a esta disyuntiva, muchos equipos utilizan múltiples niveles de caché, con pequeñas memorias caché rápidas respaldadas por grandes cachés más lentas.
Cachés multinivel generalmente operan marcando la menor nivel 1 (L1) caché primero; si golpea, el procesador procede a alta velocidad. Si la caché más pequeña falla, el siguiente mayor caché (L2) está marcada, y así sucesivamente, antes de que se comprueba la memoria externa.
Como la diferencia de latencia entre la memoria principal y la memoria caché más rápido se ha convertido en más grande, algunos procesadores han comenzado a utilizar hasta tres niveles de caché en chip. Por ejemplo, el Alfa 21164 (1995) tenía 1 a 64 MB de caché L3 fuera del chip; IBM POWER4 (2001) tenía off-chip cachés L3 de 32 MB por procesador, compartidos entre varios procesadores; la Itanium 2 (2003) tenía un 6 MB nivel unificado 3 (L3) caché en el die; la Módulo Itanium 2 (2003) MX 2 incorpora dos procesadores Itanium2 junto con un 64 MB de caché L4 compartida en un módulo multi-chip que era pines compatible con un procesador Madison; Intel Xeon MP con nombre en código de producto "Tulsa" (2006) cuenta con 16 MB de caché en el chip L3 compartida entre dos núcleos de procesamiento; el procesador AMD Phenom II (2008) tiene hasta 6 MB en-die caché L3 unificado; y la Intel Core i7 (2008) tiene un 8 MB de caché L3-die unificado que sea incluyente, compartida por todos los núcleos. Los beneficios de una caché L3 dependen de patrones de acceso de la aplicación.
Finalmente, en el otro extremo de la jerarquía de memoria, la CPU archivo de registro en sí mismo puede ser considerado el más pequeño, más rápido caché en el sistema, con la característica especial de que está prevista en software-típicamente por un compilador, ya que asigna registros para mantener valores recuperados de la memoria principal. (Véase especialmente la optimización nido bucle.) Registrar los archivos a veces también tienen jerarquía: El Cray-1 (alrededor de 1976) tenía 8 dirección 8 datos escalares registros "S" que eran generalmente utilizable "A" y. Hubo también un conjunto de 64 direcciones "B" y 64 de datos escalares registros "T" que tuvieron más tiempo para el acceso, pero eran más rápido que la memoria principal. Los "B" y los registros de "T" fueron siempre porque el Cray-1 no tiene una caché de datos. (El Cray-1 hizo, sin embargo, tiene una caché de instrucciones.)
Los chips multi-core
Al considerar un chip con varios núcleos, hay una cuestión de si los cachés deben ser compartidos o local para cada núcleo. La implementación de caché compartida, sin duda, introduce más cableado y complejidad. Pero entonces, tener una memoria caché por el chip , en vez de núcleo , reduce en gran medida la cantidad de espacio necesario, y por lo tanto se puede incluir una memoria caché más grande. Típicamente se encuentra que el intercambio de caché L1 es indeseable ya que el aumento de latencia es tal que cada núcleo se ejecutará considerablemente más lento que un chip de un solo núcleo. Pero entonces, por el más alto nivel (la última llamada antes de acceder a la memoria), que tiene un caché global es deseable por varias razones. Por ejemplo, un chip de ocho núcleos con tres niveles puede incluir una memoria caché L1 para cada núcleo, una caché L3 compartida por todos los núcleos, con la caché L2 intermedia, por ejemplo, uno para cada par de núcleos.
Separa frente unificado
En una estructura de caché por separado, las instrucciones y los datos se almacenan en caché por separado, lo que significa que una línea de caché se utiliza para almacenar en caché o bien las instrucciones o los datos, pero no ambos. En uno unificado, se elimina esta restricción.
Para ilustrar tanto la especialización y el almacenamiento en caché multinivel, aquí está la jerarquía de caché del núcleo K8 en el procesador AMDAthlon 64 CPU.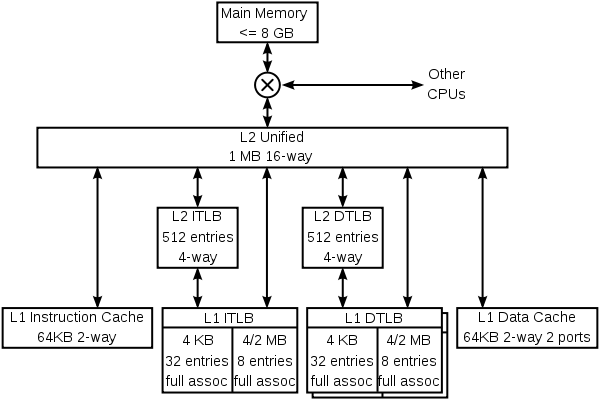
El K8 tiene 4 cachés especializadas: una caché de instrucciones, una instrucción TLB, un dato TLB y un caché de datos. Cada uno de estos escondites es especializada:
- El caché de instrucciones mantiene copias de las líneas de 64 bytes de memoria, y obtiene 16 bytes cada ciclo. Cada byte en esta memoria caché se almacena en diez bits en lugar de 8, con los bits adicionales que marcan los límites de instrucciones (este es un ejemplo de predecoding). La caché sólo tiene protección por paridad en lugar de ECC, porque la paridad es más pequeño y los datos dañados puede ser sustituido por nuevos datos se captan de la memoria (que siempre tiene una copia actualizada de las instrucciones).
- La instrucción TLB mantiene copias de las entradas de la tabla de páginas (PTE). Instrucciones de cada ciclo traiga ha traducido su dirección virtual a través de este TLB en una dirección física. Cada entrada es 4 u 8 bytes de memoria. Debido a que el K8 tiene un tamaño de página variables, cada una de las TLB está dividido en dos secciones, una para mantener PTE que mapean páginas de 4 KB, y uno para mantener PTE que se asignan 4 MB o 2 páginas MB. La división permite a los circuitos partido totalmente asociativa en cada sección sea más sencillo. El sistema operativo asigna diferentes secciones del espacio de direcciones virtuales con diferentes PTE tamaño.
- Los datos TLB tiene dos copias que mantienen entradas idénticas. Las dos copias permiten dos datos accede por ciclo de traducir direcciones virtuales a direcciones físicas. Al igual que la instrucción TLB, este TLB se divide en dos tipos de entradas.
- El caché de datos mantiene copias de las líneas de 64 bytes de memoria. Se divide en 8 bancos (cada almacenar 8 kB de datos), y puede alcanzar dos datos de 8 bytes cada ciclo, siempre y cuando esos datos se encuentran en diferentes bancos. Hay dos copias de las etiquetas, ya que cada línea de 64 bytes se extendió entre los 8 bancos. Cada copia etiqueta se encarga de uno de los dos accesos por ciclo.
El K8 también tiene cachés de nivel múltiple. Hay instrucciones y datos TLB de segundo nivel, que almacenan sólo PTE mapeo 4 kB. Ambas instrucciones y datos cachés y las diversas TLB, pueden llenar de la gran unificada caché L2. Esta caché es exclusivo tanto la instrucción L1 y cachés de datos, lo que significa que cualquier línea de 8 bytes sólo puede estar en uno de la caché L1 de instrucciones, la caché de datos L1, o la memoria caché L2. Es, sin embargo, posible que una línea en la caché de datos para tener una PTE, que es también en una de las-la TLB sistema operativo es responsable de mantener las TLB coherentes vaciando partes de ellas cuando las tablas de páginas en la memoria se actualizan.
El K8 también almacena información que nunca se almacena en información de la memoria-predicción. Estas cachés no se muestran en el diagrama anterior. Como es habitual en esta clase de CPU, el K8 tiene bastante compleja predicción de saltos, con las tablas que ayudan a predecir si se toman las ramas y otras tablas que predicen los objetivos de ramas y saltos. Parte de esta información se asocia con las instrucciones, tanto en la memoria caché de nivel 1 instrucción y la memoria caché secundaria unificada.
El K8 utiliza un truco interesante para almacenar información de predicción con las instrucciones en la memoria caché secundaria. Líneas en la memoria caché secundaria están protegidos de la corrupción accidental de datos (por ejemplo, mediante una huelga de partículas alfa) por cualquiera de las ECC o paridad, dependiendo de si esas líneas fueron desalojados de los datos o caches primarios de instrucciones. Dado que el código de paridad toma menos bits que el código ECC, líneas de la caché de instrucciones tienen unos bits de reserva. Estos bits se utilizan para almacenar en caché la información de predicción de ramificación asociada con esas instrucciones. El resultado neto es que el predictor rama tiene una mesa de la historia efectiva más grande, y por lo tanto tiene una mayor precisión.
Más jerarquías
Otros procesadores tienen otros tipos de predictores (por ejemplo, el predictor-store-a la carga de derivación en el Diciembre Alfa 21.264), y varios predictores especializados son propensos a florecer en los procesadores futuros.
Estos predictores son cachés en que almacenan información que es costoso de calcular. Algunos de los términos utilizados cuando se habla de predictores es el mismo que el de las memorias caché (se habla de un golpe en un factor de predicción de rama), pero predictores no son generalmente considerados como parte de la jerarquía de caché.
El K8 mantiene los cachés de instrucciones y datos coherentes en hardware, lo que significa que una tienda en una instrucción siguiendo de cerca la instrucción de almacenamiento va a cambiar eso siguientes instrucciones. Otros procesadores, como los de la familia Alfa y MIPS, se han basado en software para mantener la caché de instrucciones coherente. Las tiendas no están garantizados para aparecer en el flujo de instrucciones hasta que un programa llama a una instalación de sistema operativo para garantizar la coherencia.
Implementación
Caché lee son el funcionamiento de la CPU más común que lleva más de un solo ciclo. Tiempo de ejecución del programa tiende a ser muy sensibles a la latencia de un caché de datos hit nivel-1. Un gran esfuerzo de diseño, y con frecuencia el área de energía y el silicio se gastan haciendo las cachés lo más rápido posible.
El caché más simple es un caché de correlación directa prácticamente indexado. La dirección virtual se calcula con un sumador, la porción correspondiente de la dirección extraída y utilizada para un índice de SRAM, que devuelve los datos cargados. El byte de datos es alineado en una palanca de cambios byte, y desde allí se desvía a la siguiente operación. No hay necesidad de cualquier etiqueta de comprobar en el bucle interior - de hecho, las etiquetas no necesitan incluso ser leídos. Más tarde en el tintero, pero antes de que se retiró la instrucción de carga, la etiqueta para los datos cargados se debe leer, y se comprueba con la dirección virtual para asegurarse de que no fue un éxito de caché. En un fallo, la memoria caché se actualiza con la línea caché solicitada y la tubería se reinicia.
Una caché asociativa es más complicado, porque de alguna forma de la etiqueta debe ser leído para determinar qué entrada de la caché para seleccionar. Un N-manera asociativa en conjunto de nivel 1 caché normalmente lee todas las posibles etiquetas N y los datos de N en paralelo, y luego elige a los datos asociados con la etiqueta correspondiente. Cachés de nivel 2 veces ahorrar energía mediante la lectura de las etiquetas de primera, de modo que sólo un elemento de los datos se leen desde la SRAM de datos.

El diagrama de la derecha tiene la intención de aclarar la manera en que se utilizan los diversos campos de la dirección. Dirección bits 31 es más significativo, el bit 0 es menos significativo. El diagrama muestra la SRAM, indexación, y la multiplexación de 4 kB, de 2 vías asociativa en conjunto, prácticamente indexado y caché prácticamente etiquetada con 64 líneas B, un 32b leer anchura y 32 ter de direcciones virtuales.
Debido a que el caché es de 4 kB y tiene 64 líneas B, sólo hay 64 líneas en la memoria caché, y nos leen dos a la vez de una SRAM Tag que tiene 32 filas, cada uno con un par de 21 etiquetas bits. Aunque cualquier función de dirección virtual bits de 31 a 6 podría ser utilizado para indexar la etiqueta y SRAM de datos, es más simple de usar los bits menos significativos.
Del mismo modo, debido a que el caché es de 4 kB y tiene un camino de lectura 4 B, y lee dos formas para cada acceso, la SRAM de datos es de 512 filas por 8 bytes de ancho.
Un caché más moderno podría ser 16 kB, de 4 vías asociativa en conjunto, prácticamente indexado, prácticamente insinuado, y físicamente etiquetado, con 32 líneas B, 32b leer las direcciones físicas de anchura y 36b. La recurrencia ruta leer un caché como se ve muy similar a la ruta anterior. En lugar de las etiquetas, vhints se leen, y se comparan con un subconjunto de la dirección virtual. Más tarde en la tubería, la dirección virtual se traduce en una dirección física por el TLB, y la etiqueta física es leído (sólo uno, ya que los suministros que camino de la memoria caché para leer vhint). Finalmente la dirección física se compara con la etiqueta físico para determinar si se ha producido un golpe.
Algunos diseños SPARC han mejorado la velocidad de sus cachés L1 por unos retrasos de puerta por el colapso del sumador de direcciones virtuales en los decodificadores de SRAM. Ver Suma dirigida decodificador.
Historia
La historia temprana de la tecnología de caché está estrechamente ligada a la invención y el uso de la memoria virtual. Debido a la escasez y el costo de semiconductores recuerdos, ordenadores centrales tempranas en la década de 1960 utilizan una compleja jerarquía de memoria física, asignada a un espacio de memoria virtual plana utilizada por programas. Las tecnologías de memoria podrían abarcar semiconductores, magnético núcleo, tambor y disco. La memoria virtual visto y utilizado por los programas sería plana y almacenamiento en caché se utiliza para obtener los datos y las instrucciones en la memoria más rápido por delante de acceso del procesador. Se realizaron amplios estudios para optimizar los tamaños de caché. Se encontraron valores óptimos a depender en gran medida del lenguaje de programación utilizado con Algol necesitan los más pequeños y Fortran y Cobol necesitan los mayores tamaños de caché.
En los primeros días de la tecnología de microprocesador, el acceso de memoria sólo fue ligeramente más lento que el registro de acceso. Pero desde la década de 1980 la diferencia de rendimiento entre el procesador y la memoria ha ido creciendo. Los microprocesadores han avanzado mucho más rápido que la memoria, especialmente en términos de su funcionamiento frecuencia, por lo que la memoria se convirtió en un rendimiento de cuello de botella. Si bien es técnicamente posible tener toda la memoria principal tan rápido como la CPU, un camino más viable económicamente ha sido tomada: utilizar un montón de memoria de baja velocidad, sino también introducir una pequeña memoria caché de alta velocidad para paliar la brecha de rendimiento. Esto proporcionó un orden de magnitud más capacidad por el mismo precio-con solamente un rendimiento combinado ligeramente reducida.
Primeras implementaciones TLB
Los primeros usos documentados de una TLB estaban en el GE 645 y elIBM 360/67, ambos de los cuales utiliza una memoria asociativa como una TLB.
Primero caché de datos
El primer uso documentado de una caché de datos estaba en elIBMSystem / 360 Model 85.
En los microprocesadores x86
Como la microprocesadores x86 alcanzaron velocidades de reloj de 20 MHz y por encima en el 386, las pequeñas cantidades de memoria caché rápida comenzaron a aparecer en los sistemas para mejorar el rendimiento. Esto fue debido a que la DRAM utilizada para la memoria principal tenía latencia significativa, hasta 120 ns, así como ciclos de actualización. La memoria caché se construyó a partir más caro, pero significativamente más rápido, SRAM, que en el momento tenía latencias de alrededor de 10 ns. Los primeros cachés eran externa al procesador y por lo general se encuentra en la placa base en forma de ocho o nueve dispositivos DIP colocados en los alvéolos para habilitar la caché como accesorio o actualizar función.
Algunas versiones del procesador Intel 386 podrían apoyar 16 a 64kB de caché externa.
Con el Procesador 486, una memoria caché de 8 kB se integra directamente en la matriz de la CPU. Esta caché se denomina Nivel 1 o caché L1 para diferenciarla de la más lenta en la placa base, o Nivel 2 (L2). Estas cachés en la placa base eran mucho más grandes, con el tamaño más común es de 256 kB. La popularidad de la memoria caché en la placa base continuó a través de la era del Pentium MMX, pero se hizo obsoleto por la introducción de SDRAM y la creciente disparidad entre las tasas de reloj de bus y velocidades de reloj de la CPU, lo que causó la memoria caché en la placa base sea sólo un poco más rápido que la memoria principal .
El siguiente desarrollo en la implementación de caché en los microprocesadores x86 se inició con elPentium Pro, que trajo la caché secundaria en el mismo paquete que el microprocesador, velocidad de reloj de la misma frecuencia que el microprocesador.
On-motherboard cachés disfrutaron prolongados popularidad gracias a los AMD K6-2 y procesadores AMD K6-III que aún utilizan el venerable Socket 7, que fue utilizado anteriormente por Intel con cachés en la placa base. K6-III incluyó 256 kb on-die caché L2 y se aprovechó de la caché de a bordo como un tercer nivel de caché, llamada L3 (placas base con un máximo de 2 MB de caché de a bordo fueron producidos). Después de la Socket-7 quedó obsoleta, caché en la placa base desapareció de los sistemas x86.
La memoria caché de tres niveles se utilizó de nuevo en primer lugar con la introducción de múltiples núcleos de procesador, donde se añadió la L3 a la matriz CPU. Se hizo común tener los tres niveles sean más grandes en tamaño que el anterior y en la actualidad no es raro encontrar Nivel 3 tamaños de caché de ocho megabytes. Esta tendencia parece continuar en el futuro previsible.
La investigación actual
Los primeros diseños de caché se centraron exclusivamente en el costo directo de la memoria caché y la memoria RAM y la velocidad media de ejecución. Más diseños recientes de caché también consideran la eficiencia energética, la tolerancia a fallos, y otros objetivos.
Hay varias herramientas disponibles para los arquitectos informáticos para ayudar a explorar compensaciones entre ciclo de caché de tiempo, energía y materia. Estas herramientas incluyen el simulador caché CACTUS de código abierto y el conjunto de instrucciones SimpleScalar simulador de código abierto.
Caché multi-portado
Una caché multi-portado es un caché que puede servir más de una solicitud a la vez. Cuando se accede a una memoria caché tradicional que normalmente usamos una sola dirección de memoria, mientras que en una memoria caché multi-portado podemos solicitar direcciones N a la vez - donde N es el número de puertos que conectan a través del procesador y la memoria caché. El beneficio de esto es que un procesador segmentado puede acceder a la memoria de diferentes fases en su tubería. Otro beneficio es que permite que el concepto de procesadores super-escalares a través de diferentes niveles de caché.