

cache du processeur
Saviez-vous ...
Cette sélection de wikipedia a été choisi par des bénévoles aidant les enfants SOS de Wikipedia pour cette sélection Wikipedia pour les écoles. parrainage SOS enfant est cool!
Un cache de processeur est un cache utilisé par l' unité centrale de traitement d'un ordinateur afin de réduire le temps moyen d'accès mémoire. Le cache est plus petit, plus rapide mémoire qui stocke une copie des données depuis le plus fréquemment utilisé emplacements de mémoire principale. Aussi longtemps que la plupart des accès à la mémoire sont mises en cache emplacements de mémoire, le moyen latence d'accès à la mémoire sera plus proche de la latence de la mémoire cache de la latence de la mémoire principale.
Vue d'ensemble
Lorsque le processeur a besoin de lire ou d'écrire dans un emplacement dans la mémoire principale, il vérifie d'abord si une copie de données qui se trouve dans la mémoire cache. Dans l'affirmative, le processeur lit immédiatement ou écrit dans la mémoire cache, ce qui est beaucoup plus rapide que la lecture ou l'écriture vers la mémoire principale.
La plupart des CPU de bureau et serveurs modernes ont au moins trois caches indépendants: un cache d'instruction pour accélérer instruction exécutable chercher, un cache de données pour accélérer d'extraction de données et de magasin, et un Tampon de traduction (TLB) utilisé pour accélérer la traduction d'adresse virtuelle à physique pour les instructions et les données exécutables. Le cache de données est généralement organisé comme une hiérarchie de plusieurs niveaux de cache (L1, L2, etc .; voir caches multi-niveaux ).
entrées de cache
Les données sont transférées entre la mémoire et le cache en blocs de taille fixe, appelés lignes de cache. Quand une ligne de cache est copié de la mémoire dans la mémoire cache, une entrée de cache est créé. L'entrée de cache comprendra les données copiées ainsi que l'emplacement de mémoire requise (maintenant appelé tag).
Lorsque le processeur a besoin pour lire ou écrire un emplacement dans la mémoire principale, il vérifie d'abord pour une entrée correspondante dans le cache. Les contrôles de cache pour le contenu de l'emplacement de mémoire demandée dans toutes les lignes de cache pouvant contenir cette adresse. Si le processeur constate que l'emplacement de mémoire se trouve dans la mémoire cache, une opération réussie d'antémémoire se est produite (le cas contraire, un défaut de cache). Dans le cas de:
- une opération réussie d'antémémoire, le processeur lit immédiatement ou écrit les données dans la ligne de cache.
- un défaut de cache, le cache alloue une nouvelle entrée, et des copies des données de la mémoire principale. Puis, la demande est remplie à partir du contenu de la mémoire cache.
les performances du cache
La proportion d'accès qui donnent lieu à une opération réussie d'antémémoire est appelé le taux de succès, et peut être une mesure de l'efficacité de la mémoire cache d'un programme ou algorithme donné.
Lire la rate retarder l'exécution parce qu'ils nécessitent des données à transférer de la mémoire beaucoup plus lent que le cache proprement dit. Ecrire accidents peuvent se produire sans une telle peine, puisque le processeur peut continuer l'exécution tandis que les données sont copiées dans la mémoire principale en arrière-plan.
caches d'instructions sont similaires à des caches de données, mais le processeur ne effectue accès lire (instruction récupère) dans le cache d'instruction. (Avec L'architecture de Harvard et processeurs d'architecture Harvard modifiés, instructions et de données caches peuvent être séparés pour de meilleures performances, mais ils peuvent aussi être combinés pour réduire la surcharge de matériel.)
politiques de rechange
Afin de faire de la place pour la nouvelle entrée sur un défaut de cache, le cache peut avoir pour expulser une des entrées existantes. L'heuristique qu'il utilise pour choisir l'entrée d'expulser se appelle la politique de remplacement. Le problème fondamental de toute politique de remplacement, ce est qu'il doit prédire quels entrée de cache existante est moins susceptible d'être utilisé à l'avenir. Prédire l'avenir est difficile, donc il n'y a pas de moyen parfait de choisir parmi la variété des politiques de remplacement disponibles.
Une politique de remplacement populaire, moins récemment utilisé (LRU), remplace l'entrée la moins récemment consultée.
Marquage de la mémoire varie comme non-cacheable peut améliorer les performances, en évitant la mise en cache des régions de mémoire qui sont rarement nouveau accessibles. Cela évite la surcharge de charger quelque chose dans le cache, sans avoir aucune réutilisation.
- entrées de cache peuvent également être désactivé ou verrouillé en fonction du contexte.
Ecrire politiques
Si les données sont écrites dans le cache, à un certain moment, il doit également être écrit à la mémoire principale. Le calendrier de cette écriture est connu comme la politique d'écriture.
- Dans un write-through cache, chaque écriture dans le cache provoque une écriture à la mémoire principale.
- En variante, dans un reprise ou une copie-back cache, les écritures ne sont pas immédiatement en miroir à la mémoire principale. Au lieu de cela, le cache pistes quels endroits ont été écrits sur (ces endroits sont marqués sale). Les données de ces emplacements sont réécrites dans la mémoire principale que lorsque que les données sont expulsés de la mémoire cache. Pour cette raison, une miss de lecture dans un cache en écriture peut parfois nécessiter deux accès mémoire au service: l'un pour d'abord écrire l'emplacement sale à la mémoire et puis un autre de lire le nouvel emplacement de la mémoire.
Il existe des politiques intermédiaires ainsi. Le cache peut être écriture à travers, mais les écritures peut être tenue à une file d'attente de données du magasin temporairement, habituellement de sorte que plusieurs magasins peuvent être traitées ensemble (ce qui peut réduire arrêts de bus et d'améliorer l'utilisation de bus).
Les données en mémoire principale étant en cache peuvent être modifiés par d'autres entités (par exemple en utilisant des périphériques accès direct à la mémoire ou processeur multi-core), auquel cas la copie dans le cache peuvent devenir hors de date ou vicié. Sinon, lorsque le CPU dans un processeur multi-core à jour les données dans le cache, des copies des données dans les caches associés avec d'autres noyaux deviendront périmées. Les protocoles de communication entre les gestionnaires de cache qui maintiennent les données cohérentes sont connus comme protocoles de cohérence de cache.
stands de CPU
Le temps nécessaire pour aller chercher une ligne de cache de la mémoire (latence de lecture) questions parce que le CPU sera à court de choses à faire en attendant que la ligne de cache. Quand un processeur atteint cet état, il est appelé un décrochage.
Comme les processeurs deviennent plus rapides, des stands en raison de cache miss déplacent calcul plus de potentiel; processeurs modernes peuvent exécuter des centaines d'instructions dans le temps pris pour aller chercher une ligne de cache unique de la mémoire principale. Diverses techniques ont été utilisées pour maintenir le CPU occupée pendant ce temps.
- Out-of-order processeurs (Pentium designs Intel Pro et, plus tard, par exemple) tentative d'exécution d'instructions indépendantes après l'instruction qui est en attente pour les données cache miss.
- Une autre technologie, utilisée par de nombreux processeurs, est multithreading simultané (SMT), ou - dans la terminologie de Intel - Hyper-Threading (HT), qui permet un autre fil pour utiliser le noyau du CPU alors qu'un premier thread attend que les données proviennent de la mémoire principale.
la structure d'entrée de cache
des entrées de lignes de cache ont généralement la structure suivante:
| balise | bloc de données | bits indicateurs |
Le bloc de données (ligne de cache) contient les données réelles extraites de la mémoire principale. La balise contient (une partie de) l'adresse des données réelles extraites de la mémoire principale. Les bits indicateurs sont discutés ci-dessous.
La «taille» de la cache est la quantité de données de mémoire principale qu'il peut contenir. Cette taille peut être calculée comme le nombre d'octets stockés dans chacun des temps de bloc de données le nombre de blocs mémorisés dans la mémoire cache. (Le nombre de marques et de drapeau de bits est pas pertinente pour ce calcul, même si elle ne affecte pas l'espace physique d'un cache).
Une adresse de mémoire effective est divisé ( MSB à LSB) dans la balise, l'index et le décalage de bloc.
| balise | index | le décalage de bloc |
L'indice indique la ligne de cache (quelle ligne de cache) que les données ont été mis en. La longueur d'index est 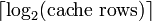 bits. Le bloc offset spécifie les données souhaitées dans le bloc de données stocké dans la ligne de cache. Typiquement l'adresse effective est en octets, de sorte que le décalage de longueur de bloc est
bits. Le bloc offset spécifie les données souhaitées dans le bloc de données stocké dans la ligne de cache. Typiquement l'adresse effective est en octets, de sorte que le décalage de longueur de bloc est 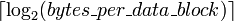 bits. L'étiquette contient les bits les plus significatifs de l'adresse, qui sont vérifiées par rapport à la ligne courante (la ligne a été récupéré par index) pour voir si elle est celle que nous devons ou un autre emplacement, de mémoire indifférent que arrivé à avoir les mêmes bits d'index que celle que nous voulons. La longueur d'étiquette en bits est
bits. L'étiquette contient les bits les plus significatifs de l'adresse, qui sont vérifiées par rapport à la ligne courante (la ligne a été récupéré par index) pour voir si elle est celle que nous devons ou un autre emplacement, de mémoire indifférent que arrivé à avoir les mêmes bits d'index que celle que nous voulons. La longueur d'étiquette en bits est 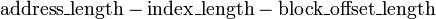 .
.
Certains auteurs se réfèrent au bloc offset simplement le «décalage» ou le «déplacement».
Exemple
Le Pentium 4 d'origine avait un ensemble cache de données à 4 voies associative L1 de la taille de 8 Ko de cache avec des blocs de 64 octets. Par conséquent, il ya 8 Ko / 64 = 128 blocs de cache. Si ce est associative à quatre voies, ce qui implique 128/4 = 32 ensembles (et donc 2 ^ 5 = 32 différents indices). Il ya 64 = 2 ^ 6 décalages possibles. Depuis l'adresse du processeur est de 32 bits, ce qui implique 32 = 21 + 5 + 6, et donc 21 bits de champ d'étiquette. Le Pentium 4 d'origine a également eu un 8-way associative cache L2 intégrée de la taille de 256 Ko avec 128 blocs de cache d'octets. Cela implique 32 = 17 + 8 + 7, et donc 17 bits de champ d'étiquette.
bits de drapeau
Une cache d'instruction ne nécessite qu'un seul bit de drapeau par entrée de ligne de cache: un bit valide. Le bit de validité indique si oui ou non un bloc de cache a été chargée avec des données valides.
Au démarrage, le matériel fixe tous les bits valides dans tous les caches à «invalide». Certains systèmes également mis un peu valide pour «invalide» à d'autres moments-comme lorsque multi-maître bus snooping matériel dans le cache d'un processeur entend une adresse de diffusion d'un autre processeur, et se rend compte que certains blocs de données dans le cache local sont désormais périmées et devraient être marqués invalide.
Un cache de données nécessite généralement deux bits de drapeau par cache entrée de rang: un bit valide et aussi un peu sale. Le peu sale indique si ce bloc n'a pas changé depuis qu'il a été lu dans la mémoire principale - «propre», ou si le processeur a écrit des données à ce bloc (et la nouvelle valeur n'a pas encore fait tout le chemin à la mémoire principale) - «sale».
Associativité
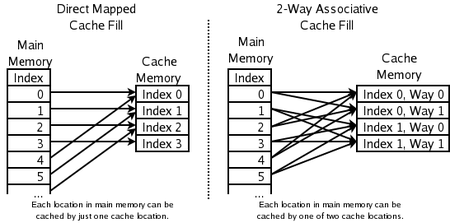
La politique de remplacement décide où dans le cache une copie d'une entrée particulière de la mémoire principale ira. Si la politique de remplacement est libre de choisir ne importe quelle entrée dans le cache de tenir la copie, le cache est appelé entièrement associative. À l'autre extrême, si chaque entrée dans la mémoire principale peut aller dans un seul endroit dans le cache, le cache est directement mappé. Beaucoup de caches mettre en œuvre un compromis dans lequel chaque entrée dans la mémoire principale peut aller l'une quelconque des N endroits dans le cache, et sont décrites comme jeu N-way associative. Par exemple, le cache de données de niveau 1 dans un AMD Athlon est associative à deux voies, ce qui signifie que ne importe quel endroit particulier dans la mémoire principale peut être mis en cache dans l'une des deux endroits dans le cache de données de niveau 1.
Associativité est un troquer. Se il ya dix lieux où la politique de remplacement aurait pu mappés un emplacement mémoire, puis de vérifier si ce dossier est dans le cache, dix entrées de cache doivent être recherchés. Vérification plusieurs endroits prend plus de puissance, surface de la puce, et potentiellement le temps. D'autre part, les caches avec plus associativité souffrent moins de justesse (voir justesse de conflit, ci-dessous), de sorte que les déchets de CPU moins de temps à lire de la mémoire principale lente. La règle de base est que le doublement de l'associativité, à partir directement mappé à 2 voies, ou de 2 voies à 4 voies, a le même effet sur le taux de succès que doubler la taille du cache. Associativité augmente au-delà 4 voies ont beaucoup moins d'effet sur le taux de succès, et sont généralement faites pour d'autres raisons (voir aliasing virtuel, ci-dessous).
Afin de pire, mais simple à mieux, mais complexe:
- cache directe mappé - Les meilleurs (plus rapide) hit fois, et ainsi le meilleur compromis pour les "grands" caches
- 2-way set cache associative
- 2-way biaisée de cache associative - Le meilleur compromis pour les caches dont les tailles sont dans la gamme 4K 8K-octets.
- 4-way set cache associative
- cache entièrement associative - les meilleurs (les plus faibles) taux miss, et ainsi le meilleur compromis lorsque la peine de manquer est très élevé
Cache direct mapped
Ici, chaque emplacement de la mémoire principale ne peut aller dans une entrée dans le cache. Il n'a pas une politique de remplacement en tant que telle, car il n'y a pas de choix dont le contenu de l'entrée de cache d'expulser. Cela signifie que si deux emplacements correspondent à la même entrée, ils peuvent toujours frapper les uns les autres. Bien que simple, un cache à correspondance directe doit être beaucoup plus grand qu'un associatifs pour donner des performances comparables, et est plus imprévisible.
2-way set cache associative
Si chaque emplacement dans la mémoire principale peut être mis en cache dans deux emplacements dans le cache, une question logique est: lequel des deux Le système le plus simple et le plus couramment utilisé, indiqué dans le schéma de droite ci-dessus, est d'utiliser le bits les moins significatifs de l'indice de l'emplacement de mémoire que l'indice de la mémoire cache, et ont deux entrées pour chaque indice. Un des avantages de ce système est que les étiquettes stockées dans le cache ne ont pas à inclure cette partie de l'adresse de mémoire principale qui est impliquée par l'indice de la mémoire cache. Depuis les étiquettes d'antémémoire ont moins de bits, ils prennent moins d'espace sur la puce de microprocesseur et peut être lu et comparé plus rapide. Aussi LRU est particulièrement simple car un seul bit doit être stocké pour chaque paire.
Exécution spéculative
Un des avantages d'un cache mappé directe est qu'il permet simple et rapide la spéculation. Une fois que l'adresse a été calculé, l'indice d'un cache qui pourrait avoir une copie de cet emplacement en mémoire est connu. Cette entrée de cache peut être lu, et le processeur peut continuer à travailler avec ces données avant de terminer la vérification que l'étiquette correspond effectivement à l'adresse demandée.
L'idée d'avoir le processeur utilise les données mises en cache avant les terminée tag match peut être appliqué à associatifs caches ainsi. Un sous-ensemble de l'étiquette, appelée un soupçon, peut être utilisé pour choisir un seul de la possible cartographie des entrées de cache à l'adresse demandée. L'entrée sélectionnée par le soupçon peut ensuite être utilisé en parallèle avec la vérification de la balise complète. La technique de pointe fonctionne mieux quand il est utilisé dans le contexte de traduction d'adresse, comme expliqué ci-dessous.
2-way biaisée de cache associative
Autres régimes ont été proposés, tels que le cache asymétrique, où l'indice pour la voie 0 est directe, comme ci-dessus, mais l'indice de manière 1 est formée avec une fonction de hachage. Une bonne fonction de hachage a la propriété qui traite qui entrent en conflit avec le mappage direct tend pas à des conflits lors de la projection avec la fonction de hachage, et il est donc moins probable qu'un programme souffrir d'un nombre inattendu de conflit rate en raison d'un accès pathologique motif. L'inconvénient est la latence supplémentaire de calcul de la fonction de hachage. En outre, lorsque vient le temps de charger une nouvelle ligne et d'expulser une ancienne ligne, il peut être difficile de déterminer ce qui a été ligne existante moins récemment utilisé, parce que les nouveaux conflits de ligne avec des données à différents indices dans chaque sens; Suivi LRU pour les caches non-biaisées se fait généralement sur une base per-mis. Néanmoins, caches asymétriques associatif ont des avantages majeurs sur les set-associative classiques.
cache pseudo-associative
Un véritable jeu de cache-associative teste tous les moyens possibles simultanément, en utilisant quelque chose comme un mémoire adressable par contenu. Un cache de pseudo-associatif teste chaque chemin possible une à la fois. Un cache-resucée hachage et un cache de colonne associatif sont des exemples de cache de pseudo-associatif.
Dans le cas fréquent de trouver un succès de la première manière testé, un cache de pseudo-associatif est aussi rapide qu'un cache en correspondance directe. Mais il a un taux de miss conflit beaucoup inférieur à un cache à correspondance directe, plus proche du taux d'un cache entièrement associative miss.
Cache manquer
A défaut de cache fait référence à une tentative avortée de lire ou d'écrire un morceau de données dans le cache, ce qui se traduit par un accès de mémoire principale avec beaucoup plus de latence. Il existe trois types de défauts de cache: lecture d'instruction miss, données lues miss, et d'écriture de données manquer.
Un cache lu Mlle d'une cache d'instruction provoque généralement le plus de retard, parce que le processeur, ou du moins la thread d'exécution, doit attendre (décrochage) jusqu'à ce que l'instruction est extraite de la mémoire principale.
Un cache de lecture manqué d'un cache de données provoque généralement moins de retard, parce que les instructions ne dépendant pas de la lecture de cache peuvent être émises et continuent exécution jusqu'à ce que les données sont renvoyées de la mémoire principale, et les instructions dépendantes peut reprendre l'exécution.
Un cache écriture manquer à un cache de données provoque généralement le moindre retard, parce que l'écriture peut être en file d'attente et il ya quelques limitations sur l'exécution des instructions ultérieures. Le processeur peut continuer jusqu'à ce que la file d'attente est pleine.
Afin de réduire les taux de défaut de cache, une grande partie de l'analyse a été faite sur le comportement du cache dans une tentative de trouver la meilleure combinaison de la taille, associativité, taille de bloc, et ainsi de suite. Séquences de références de mémoire effectuées par des programmes de référence sont enregistrés en tant que traces d'adresse. Des analyses ultérieures simuler de nombreux designs possible de cache sur ces traces d'adresses longues. Donner un sens de la façon dont les nombreuses variables influent sur le taux d'utilisation du cache peut être assez déroutant. Une contribution significative à cette analyse a été faite par Mark Hill, qui se est séparé de justesse en trois catégories (connu sous le nom des Trois Cs):
- Manque obligatoires sont ces accidents causés par la première référence à un emplacement en mémoire. Taille du cache et l'associativité ne font aucune différence au nombre d'échecs obligatoires. Préchargement peut aider ici, comme des tailles de bloc plus grande de cache (qui sont une forme de prefetching). Manque obligatoires sont parfois appelés accidents que froides.
- manque de capacité sont les accidents qui se produisent indépendamment de l'associativité ou la taille de bloc, uniquement en raison de la taille limitée de la mémoire cache. La courbe de taux de manquer de capacité par rapport à la taille du cache donne une mesure de la localisation temporelle d'un courant de référence particulier. Notez qu'il n'y a pas de notion utile d'un cache étant «complet» ou «vide» ou «presque à pleine capacité": caches CPU ont presque toujours à peu près chaque ligne rempli d'une copie de quelque ligne de la mémoire principale, et presque chaque attribution d'une nouvelle ligne nécessite l'expulsion d'une ancienne ligne.
- manque de conflit sont les accidents qui auraient pu être évitées, avaient le cache pas expulsés à une date antérieure. manque de conflits peuvent être subdivisées en manque de cartographie, qui sont inévitables étant donné une quantité particulière de l'associativité, et manque de remplacement, qui sont dues au choix de la victime notamment de la politique de remplacement.

Le graphique de droite présente le rendement de cache vu sur la partie entière de la benchmarks SPEC CPU2000, telles que recueillies par Hill et Cantin. Ces repères sont destinés à représenter le type de charge de travail qu'un poste de travail d'ingénierie pourrait voir un jour donné. Le lecteur doit garder à l'esprit que la recherche de repères qui sont encore utilement représentant de nombreux programmes a été très difficile, et il y aura toujours d'importants programmes au comportement très différent de ce qui est montré ici.
Nous pouvons voir les différents effets des trois Cs dans ce graphique.
Au extrême droite, avec la taille de cache marqué "Inf", nous avons les accidents obligatoires. Si nous voulons améliorer la performance d'une machine sur SPECint2000, en augmentant la taille du cache au-delà de 1 Mo est essentiellement futile. Ce est l'intuition donnée par les accidents obligatoires.
Le taux de défaut de cache entièrement associative ici est presque représentant du taux de miss capacités. La différence est que les données présentées sont des simulations supposant une Politique de remplacement LRU. Afficher le taux capacités miss nécessiterait une politique de remplacement parfait, ce est à dire un oracle qui ressemble à l'avenir de trouver une entrée de cache qui est fait ne va pas être frappé.
Notez que notre rapprochement du taux de miss capacité tombe à pic entre 32 kB et 64 ko. Ceci indique que l'indice de référence a une jeu de travail d'environ 64 ko. Un concepteur de cache du processeur d'examiner ce point de référence aura un fort intérêt à définir la taille du cache à 64 Ko plutôt que 32 Ko. Notez que, sur ce point de repère, aucun montant de l'associativité peut faire un cache 32 kB effectuer ainsi que 64 Ko à 4 voies, ou même un 128 Ko de cache à correspondance directe.
Enfin, notez que entre 64 Ko et 1 Mo il ya une grande différence entre caches directs mappés et entièrement associatives. Cette différence est le taux de miss conflit. L'idée de regarder à taux de manquer de conflit est que les caches secondaires bénéficient beaucoup de la haute associativité.
Cet avantage était bien connu dans les années 80 et au début des années 90, lorsque les concepteurs de CPU ne ont pas pu se adapter à de grandes caches sur puce, et n'a pas pu obtenir suffisamment de bande passante soit sur la mémoire cache de données ou une étiquette mémoire cache pour mettre en œuvre haute associativité dans des caches hors puce . Hacks Housewives ont été tentées: le MIPS R8000 utilisé cher hors puce tag dédié SRAM, qui avaient embarqués comparateurs de tag et de grands pilotes sur les lignes de match, afin de mettre en œuvre un 4 Mo à 4 voies cache associative. Le MIPS R10000 utilisé puces SRAM ordinaires pour les tags. accès Tag pour les deux façons fallu deux cycles. Pour réduire la latence, le R10000 serait deviner de quel côté de la cache aurait frappé sur chaque accès.
La traduction d'adresse
La plupart des processeurs à usage général de mettre en œuvre une certaine forme de mémoire virtuelle. Pour résumer, chaque programme se exécutant sur la machine voit sa propre simplifiée espace d'adressage, qui contient du code et des données pour seulement ce programme. Chaque programme utilise cet espace d'adressage virtuel, sans égard pour le cas où elle existe dans la mémoire physique.
Mémoire virtuelle nécessite le processeur pour traduire des adresses virtuelles générées par le programme en adresses physiques dans la mémoire principale. La partie du processeur qui ne cette traduction est connu comme le Unité de gestion de mémoire (MMU). Le chemin d'accès rapide par la MMU peut effectuer ces traductions stockées dans la Tampon de traduction (TLB), qui est un cache de mappage à partir du système d'exploitation de table de page.
Aux fins de la présente discussion, il ya trois éléments importants de traduction d'adresse:
- Latence: L'adresse physique est disponible auprès de la MMU un certain temps, peut-être quelques cycles, après l'adresse virtuelle est disponible à partir du générateur d'adresses.
- Aliasing: adresses virtuelles multiples peuvent mapper vers une adresse physique unique. La plupart des processeurs garantissent que tous les mises à jour de cette adresse physique unique qui se passera dans l'ordre du programme. Pour se acquitter de cette garantie, le processeur doit se assurer qu'une seule copie d'une adresse physique se trouve dans le cache à un moment donné.
- Granularité: L'espace d'adressage virtuel est divisé en pages. Par exemple, un 4 Go espace d'adressage virtuel peut être découpé en 1.048.576 pages de 4 Ko de taille, dont chacun peut être mappés indépendamment. Il peut y avoir plusieurs formats de page pris en charge; voir mémoire virtuelle pour l'élaboration.
Une note historique: certains systèmes de mémoire virtuelle début était très lent, car elles nécessitaient un accès à la table de page (tenue à la mémoire principale) avant chaque accès programmé à la mémoire principale. En l'absence de cache, cette coupe efficacement la vitesse de la machine en deux. Le premier cache matériel utilisé dans un système informatique ne était pas en fait un cache de données ou d'instructions, mais plutôt un TLB.
Les caches peuvent être divisés en quatre types, selon que l'indice ou de l'étiquette correspondent à des adresses physiques ou virtuels:
- Physiquement indexé, marqués physiquement (PIPT) caches utilisent l'adresse physique pour l'indice et l'étiquette. Bien que ce est simple et évite les problèmes avec aliasing, il est aussi lent, que l'adresse physique doit être leva les yeux (ce qui pourrait impliquer une miss TLB et l'accès à la mémoire principale) avant cette adresse peut être recherchée dans le cache.
- Pratiquement indexé, pratiquement marqués (VIVT) caches utilisent l'adresse virtuelle à la fois pour l'indice et l'étiquette. Ce système de mise en cache peut entraîner des recherches beaucoup plus rapides, puisque la MMU n'a pas besoin d'être consultés d'abord déterminer l'adresse physique pour une adresse virtuelle donnée. Cependant, VIVT souffre de problèmes d'aliasing, où plusieurs adresses virtuelles différentes peuvent se référer à la même adresse physique. Le résultat est que ces adresses seront mises en cache séparément en dépit de référence à la même mémoire, provoquant des problèmes de cohérence. Un autre problème est homonymes, où la même adresse virtuelle Cartes à plusieurs adresses physiques différentes. Il ne est pas possible de distinguer ces mappages en ne regardant à l'index virtuel, si les solutions possibles comprennent: vider le cache après une changement de contexte, forçant espaces d'adressage d'être non-chevauchement, le marquage de l'adresse virtuelle avec un ID d'espace d'adresse (ASID), ou en utilisant des étiquettes physiques. En outre, il ya un problème que virtuel-physique mappages peuvent changer, ce qui nécessiterait rinçage lignes de cache, comme le SAV ne serait plus valide.
- , Marqués physiquement (VIPT) caches Pratiquement indexés utilisent l'adresse virtuelle pour l'index et l'adresse physique dans la balise. L'avantage par rapport PIPT est une latence plus faible, comme la ligne de cache peut être considérée en parallèle avec la traduction TLB, mais l'étiquette ne peut être comparée jusqu'à l'adresse physique est disponible. L'avantage par rapport VIVT est que, depuis la balise possède l'adresse physique, le cache peut détecter homonymes. VIPT nécessite plus de bits d'étiquette, que les bits d'index ne représentent plus la même adresse.
- Physiquement indexé, pratiquement marqués (PIVT) caches ne sont que théoriques car ils seraient pour l'essentiel inutile.
La vitesse de cette récurrence (le temps de latence de charge) est cruciale pour les performances du processeur, et ainsi plus modernes niveau 1 caches sont quasiment indexé, ce qui permet au moins TLB la recherche de la MMU de procéder en parallèle avec la récupération des données du cache RAM.
Mais indexation virtuelle ne est pas le meilleur choix pour tous les niveaux de cache. Le coût de traiter les alias virtuels croît avec la taille de la mémoire cache, et par conséquent la plupart de niveau 2 et les grandes caches sont indexés physiquement.
Caches ont toujours utilisé les deux adresses virtuelles et physiques pour les étiquettes d'antémémoire, bien marquage virtuelle est maintenant rare. Si la recherche TLB peut terminer avant la recherche de cache RAM, l'adresse physique est disponible à temps pour comparer tag, et il ne est pas nécessaire pour le marquage virtuel. Grandes caches, puis, ont tendance à être marqués physiquement, et seulement de petites caches de latence très faibles sont pratiquement étiquetés. Dans processeurs récents d'usage général, le marquage virtuelle a été remplacé par vhints, comme décrit ci-dessous.
Homonymes et synonymes problèmes
Le cache qui repose sur l'indexation et le marquage virtuel devient incompatible après la même adresse virtuelle est mappé dans différentes adresses physiques ( homonyme). Cela peut être résolu en utilisant l'adresse physique pour le marquage ou en stockant l'espace adresse id dans la ligne de cache. Cependant, le dernier de ces deux approches ne aide pas contre le problème de synonymes, où plusieurs lignes d'antémémoire finissent stocker des données pour la même adresse physique. Écrit à tel endroit peut mettre à jour un seul endroit dans le cache, en laissant les autres avec des données incohérentes. Ce problème pourrait être résolu par l'aide des configurations de mémoire non se chevauchent pour les différents espaces d'adressage ou autrement, le cache (ou une partie de celui-ci) doit être rincée lorsque les modifications de mappage.
Tags et vhints virtuelles
Le grand avantage de balises virtuelles est que, pour les caches associatifs, ils permettent au match d'étiquette de procéder avant le virtuel à la traduction physique est fait. Cependant,
- sondes de cohérence et les expulsions présentent une adresse physique d'action. Le matériel doit avoir un moyen de convertir les adresses physiques dans un index de mémoire cache, généralement en stockant balises physiques ainsi que des balises virtuelles. A titre de comparaison, un cache physiquement marqué n'a pas besoin que les étiquettes restent virtuelles, qui est plus simple.
- Quand un virtuel pour la cartographie physique est supprimé du TLB, les entrées de cache avec ces adresses virtuelles devront être rincé en quelque sorte. Alternativement, si les entrées de cache sont autorisés sur les pages non cartographiés par le TLB, alors ces entrées devront être rincé lorsque les droits d'accès sur ces pages sont modifiées dans le tableau de la page.
Il est également possible pour le système d'exploitation pour se assurer qu'aucun alias virtuels sont simultanément résident dans la mémoire cache. Le système d'exploitation fait de cette garantie par l'application de coloriage, qui est décrit ci-dessous. Certains processeurs RISC début (SPARC, RS / 6000) ont cette approche. Il n'a pas été utilisé récemment, que le coût du matériel de détection et d'expulsion alias virtuels a diminué et la complexité du logiciel et de la pénalité de performance parfaite coloration page a augmenté.
Il peut être utile de distinguer les deux fonctions de balises dans un cache associatif: ils sont utilisés pour déterminer quel chemin de l'entrée fixé pour sélectionner, et ils sont utilisés pour déterminer si le cache touché ou manqué. La deuxième fonction doit toujours être correcte, mais il est permis pour la première fonction à deviner, et d'obtenir la mauvaise réponse occasionnellement.
Certains processeurs (par exemple début SPARCS) ont caches avec les deux balises virtuels et physiques. Les balises virtuels sont utilisés pour la sélection de chemin, et les balises physiques sont utilisés pour déterminer tout ou rien. Ce type de cache bénéficie de l'avantage d'un temps de latence cache pratiquement balisé, et l'interface logicielle simple d'un cache physiquement marqué. Elle porte le coût supplémentaire des étiquettes dupliquées, cependant. En outre, pendant le traitement de miss, les autres moyens de la ligne de cache indexées doivent être sondé pour les alias virtuels et tout matchs expulsées.
La zone supplémentaire (et une certaine latence) peuvent être atténués en gardant des notes virtuelles à chaque entrée à la place de balises virtuelles de cache. Ces conseils sont un sous-ensemble ou de hachage de la balise virtuelle, et sont utilisées pour sélectionner le chemin de la mémoire cache à partir de laquelle d'obtenir des données et une étiquette physique. Comme un cache pratiquement balisé, il peut y avoir un match de soupçon, mais tag décalage physique virtuelle, dans ce cas, l'entrée de cache avec l'indice correspondant doit être expulsé sorte que cache accède après la cache remplir à cette adresse aura un seul match de conseil. Depuis conseils virtuels ont moins de bits que les étiquettes virtuelles qui les distinguent les uns des autres, un cache pratiquement laissé entendre souffre plus de manque de conflit que d'un cache pratiquement balisé.
Peut-être la réduction définitive de notes virtuels peut être trouvé dans les Pentium 4 Willamette (noyaux et Northwood). Dans ces processeurs du soupçon virtuelle est effectivement 2 bits, et le cache est associative 4 voies. En effet, le matériel maintient une simple permutation de l'adresse virtuelle à l'index de la mémoire cache, de sorte qu'aucune contenu mémoire adressable (CAM) est nécessaire pour sélectionner le droit l'une des quatre façons par les cheveux.
Coloriage
Grandes caches physiquement indexées (généralement des caches secondaires) rencontrez un problème: le système d'exploitation plutôt que les contrôles de l'application qui se entrechoquent pages avec l'autre dans le cache. Les différences dans l'allocation de pages d'un programme de fonctionner à l'autre conduisent à des différences dans les habitudes cache de collision, ce qui peut conduire à de très grandes différences dans la performance du programme. Ces différences peuvent rendre très difficile d'obtenir un calendrier cohérent et reproductible pour une course de référence.
Pour comprendre le problème, envisager un CPU avec une MB physiquement indexé niveau 2 cache direct mapped et pages de 4 Ko de mémoire virtuelle. Pages physiques séquentielles correspondent aux emplacements séquentiels dans le cache qu'après 256 pages le modèle se enroule autour. Nous pouvons étiqueter chaque page physique avec une couleur de 0-255 pour désigner où dans le cache, il peut aller. Endroits à l'intérieur des pages physiques avec des couleurs différentes ne peuvent pas entrer en conflit dans le cache.
Un programmeur essayant de faire une utilisation maximale de la mémoire cache peut organiser les modèles d'accès de son programme de sorte que seuls 1 Mo de données doivent être mis en cache à un moment donné, évitant ainsi de justesse de capacité. Mais il doit aussi se assurer que les modèles d'accès ne ont pas manque de conflit. Une façon de penser à propos de ce problème est de diviser les pages virtuelles le programme utilise et leur attribuer des couleurs virtuelles de la même manière que les couleurs physiques ont été affectés à des pages physiques avant. Le programmeur peut alors organiser les motifs de son code d'accès de sorte que deux pages de la même couleur virtuelle sont utilisés en même temps. Il ya une grande littérature sur ces optimisations (par exemple, boucle de l'optimisation du nid), venant en grande partie de la High Performance Computing (HPC) de la communauté.
Le hic, ce est que, bien que toutes les pages de l'utilisation à un moment donné peuvent avoir des couleurs différentes virtuelles, certains peuvent avoir les mêmes couleurs physiques.En fait, si le système d'exploitation affecte pages physiques vers des pages virtuelles de façon aléatoire et uniformément, il est très probable que certaines pages auront la même couleur physique, puis les emplacements de ces pages vont entrer en collision dans le cache (ce qui est leparadoxe de l'anniversaire).
La solution est d'avoir la tentative de système d'exploitation pour affecter différentes pages de couleur physique à différentes couleurs virtuels, une technique appelée coloriage . Bien que la cartographie réelle du virtuel à la couleur physique est sans rapport avec les performances du système, applications impairs sont difficiles à suivre et peu d'avantages, donc la plupart des approches de coloriage simplement essayer de garder les couleurs physiques et virtuels de page même.
Si le système d'exploitation peut garantir que chacune des cartes physiques de pages à une seule couleur virtuelle, alors il n'y a pas alias virtuels, et le processeur peuvent utiliser des caches quasiment indexés sans avoir besoin de sondes d'alias virtuels supplémentaires lors de la manipulation de manquer. Alternativement, l'O / S peut vider une page à partir du cache chaque fois qu'il change d'une couleur virtuelle à l'autre. Comme mentionné ci-dessus, cette approche a été utilisée pour certains SPARC début et RS / 6000 dessins.
hiérarchie de cache dans un processeur moderne

Les processeurs modernes ont de multiples caches interagissant sur puce.
Le fonctionnement d'un cache particulier peut être complètement spécifié par:
- la taille du cache
- la taille de bloc du cache
- le nombre de blocs dans un ensemble
- la politique de remplacement de cache définir
- la politique cache d'écriture (write-through ou reprise)
Bien que tous les blocs de cache dans un cache particulier, sont de la même taille et le même associativité, typiquement caches "de niveau inférieur" (tels que le cache L1) ont une taille plus petite, ont de plus petits blocs, et ont moins de blocs dans un ensemble , tandis que les caches "de niveau supérieur" (tels que le cache L3) ont une plus grande taille, de plus grands blocs, et plusieurs blocs dans un ensemble.
Caches spécialisés
Pipeline mémoire de CPU à partir de plusieurs points de la pipeline: extraction d'instruction, la traduction d'adresse virtuelle à physique, et d'extraction de données (voir pipeline classique RISC). La conception naturelle est d'utiliser différents caches physiques pour chacun de ces points, de sorte que pas une ressource physique doit être prévue pour desservir deux points dans le pipeline. Ainsi le pipeline se termine naturellement avec au moins trois caches séparés (instruction, TLB, et de données), chacune spécialisée à son rôle particulier.
Pipelines d'instructions et de données caches séparés, désormais prédominants, sont dit avoir une architecture de Harvard. À l'origine, cette phrase fait référence à des machines avec instructions et de données des mémoires séparées, qui se sont avérés ne pas du tout populaire. La plupart des processeurs modernes ont une mémoire unique architecture de von Neumann.
cache des victimes
Un cache de la victime est un cache utilisé pour contenir des blocs expulsées d'un cache du processeur lors de leur remplacement. Le cache de la victime se trouve entre la cache principale et son chemin de recharge, et ne détient que des blocs qui ont été expulsées de la cache principale. Le cache de la victime est généralement entièrement associative, et est destiné à réduire le nombre d'accidents de conflit. Beaucoup de programmes couramment utilisés ne nécessitent pas une cartographie associative pour tous les accès. En fait, seule une petite fraction de l'accès à la mémoire du programme exigent haute associativité. Le cache de la victime exploite en fournissant haute associativité à ces seuls accès de cette propriété. Il a été introduit par Norman Jouppi de DEC en 1990.
cache de Trace
Un des exemples les plus extrêmes de cache spécialisation est le cache de trace trouvés dans les processeurs Intel Pentium 4 microprocesseurs. Un cache de trace est un mécanisme pour augmenter l'instruction chercher bande passante et la consommation d'énergie (dans le cas du Pentium 4) en stockant des traces d' instructions qui ont déjà été récupérées et décodés.
La publication universitaire plus tôt largement reconnu de cache de trace était parEric Rotenberg,Steve Bennett etJim Smith dans leur rapport de 1996«Trace Cache: une latence faible approche à l'instruction de haute bande passante Comparaison."
Une publication antérieure est le brevet américain 5,381,533, «Dynamic mémoire cache d'instruction de flux organisé autour de segments de traces indépendants de la ligne d'adresse virtuelle", parAlex Peleg etUri Weiser d'Intel Corp., de brevet déposée le 30 Mars 1994, la poursuite d'une demande déposée en 1992, abandonné par la suite.
A magasins de cache de trace des instructions, soit après qu'ils ont été décodés, ou comme ils sont à la retraite. Généralement, les instructions sont ajoutées à tracer caches dans les groupes représentant soit individuels blocs de base ou des traces d'instructions dynamiques. Une trace dynamique («chemin de trace") ne contient que des instructions dont les résultats sont réellement utilisés, et élimine les instructions ci-dessous branches prises (car ils ne sont pas exécutées); une trace dynamique peut être une concaténation de plusieurs blocs de base. Ceci permet à l'unité d'extraction d'instruction d'un processeur pour aller chercher plusieurs blocs de base, sans avoir à vous soucier de branches dans le flux d'exécution.
Tracez des lignes sont stockés dans le cache de trace sur la base du compteur de programme de la première instruction dans la trace et un ensemble de prédictions de branchement. Cela permet de stocker différents chemins de trace qui commencent à la même adresse, chacun représentant différents résultats de la branche. Dans la recherche d'instructions étape d'un pipeline, le compteur de programme en cours avec un ensemble de prédictions de branchement est cochée dans le cache de trace d'un succès. Si il est un succès, une ligne de suivi est fourni pour aller chercher ce qui ne doit pas aller à un cache régulière ou à la mémoire de ces instructions. Le cache de trace continue d'alimenter l'unité d'extraction jusqu'à ce que la ligne de trace se termine ou jusqu'à ce que il ya une erreur de prédiction dans le pipeline. Si il ya un manque, une nouvelle trace commence à être construit.
Oligo caches sont également utilisés dans les processeurs tels queIntel Pentium 4 pour stocker des micro-opérations déjà décodés, ou des traductions d'instructions x86 complexes, de sorte que la prochaine fois qu'une instruction est nécessaire, il n'a pas à être décodé à nouveau.
Caches multi-niveaux
Un autre problème est le compromis fondamental entre la latence du cache et de taux de succès. Les plus gros caches ont un meilleur taux de succès mais plus la latence. Pour faire face à ce compromis, de nombreux ordinateurs utilisent plusieurs niveaux de cache, avec de petites caches rapides sauvegardés par les grandes caches plus lents.
Caches multi-niveaux fonctionnent généralement en cochant la plus petite de niveau 1 (L1) cache de premier; si elle frappe, le processeur passe à grande vitesse. Si le petit cache manque, la prochaine grande cache (L2) est cochée, et ainsi de suite, avant que la mémoire externe est cochée.
Comme la différence de latence entre la mémoire principale et le cache plus rapide est devenu plus grand, certains transformateurs ont commencé à utiliser autant que trois niveaux de cache sur puce. Par exemple, le Alpha 21164 (1995) avait 1 à 64 Mo L3 hors puce cache; IBM Power4 (2001) avait hors puce L3 caches de 32 Mo par processeur, partagées entre plusieurs processeurs; la Itanium 2 (2003) a eu un 6 Mo niveau unifié 3 (L3) cache sur puce; la Module Itanium 2 (2003) MX 2 intègre deux processeurs Itanium 2 avec un 64 Mo de cache L4 partagé sur un module de multi-puce qui était compatible broche à broche avec un processeur Madison; Intel Xeon MP produit le nom de code "Tulsa" (2006) dispose de 16 Mo de on-die cache L3 partagé entre deux cœurs de processeur; l'AMD Phenom II (2008) a jusqu'à 6 Mo sur-Dié cache L3 unifié; et le Intel Core i7 (2008) a un 8 Mo sur-die cache L3 unifié qui est inclusive, partagée par tous les cœurs. Les avantages d'un cache L3 dépendent des modèles d'accès de l'application.
Enfin, à l'autre extrémité de la hiérarchie mémoire, la CPU fichier de registres lui-même peut être considérée comme la plus petite, la plus rapide cache dans le système, avec la particularité qu'il est prévu dans le logiciel, typiquement par un compilateur, comme il alloue registres à tenir valeurs récupérées de la mémoire principale. (Voir notamment l'optimisation de la boucle nid.) Créer des fichiers parfois ont également hiérarchie: Le Cray-1 (circa 1976) avait 8 adresse "A" et 8 données scalaires de registres "S" qui étaient généralement utilisable. Il y avait aussi un ensemble de 64 adresses "B" et 64 données scalaires registres "T" qui ont eu plus de temps pour l'accès, mais étaient plus rapides que la mémoire principale. Les «B» et les registres "T" ont été fournis parce que le Cray-1 n'a pas eu un cache de données. (Le Cray-1 n'a, cependant, ont une mémoire cache d'instruction.)
Puces multi-core
Lors de l'examen d'une puce avec plusieurs cœurs, il ya une question de savoir si les caches doivent être partagés ou local pour chaque noyau. Mise en œuvre de mémoire cache partagée introduit sans doute plus le câblage et la complexité. Mais alors, ayant une mémoire cache par puce , plutôt que de base , réduit considérablement la quantité d'espace nécessaire, et donc on peut inclure une plus grande mémoire cache. Typiquement, on trouve que le partage de cache L1 est indésirable car l'augmentation de latence est telle que chaque noyau se déroulera beaucoup plus lent que d'une puce single-core. Mais alors, pour le plus haut niveau (le dernier appelé avant d'accéder à la mémoire), ayant un cache global est souhaitable pour plusieurs raisons. Par exemple, une puce à huit cœurs avec trois niveaux peut inclure un cache L1 pour chaque core, d'un cache L3 partagé par tous les cœurs, avec le cache L2 intermédiaire, par exemple, un pour chaque paire de noyaux.
Séparée par rapport unifié
Dans une structure de cache séparé, instructions et de données sont mises en cache séparément, ce qui signifie que une ligne de cache est utilisé pour mettre en cache soit des instructions ou des données, mais pas les deux. Dans un un unifiée, cette contrainte est supprimée.
Pour illustrer à la fois la spécialisation et la mise en cache à plusieurs niveaux, voici la hiérarchie de cache du noyau K8 dans le AMDAthlon 64 CPU.
Le K8 dispose de 4 caches spécialisés: une cache d'instruction, une instruction TLB, une donnée TLB, et un cache de données. Chacun de ces caches est spécialisée:
- Le cache d'instruction conserve des copies des lignes de 64 octets de mémoire, et récupère 16 octets chaque cycle. Chaque octet dans ce cache est stocké dans dix bits plutôt que 8, avec les bits supplémentaires qui marquent les limites des instructions (ceci est un exemple de prédécodage). Le cache ne dispose que d' une protection de la parité plutôt que ECC parce que la parité est plus petit et toutes les données endommagées peut être remplacé par de nouvelles données lues à partir de la mémoire (qui a toujours une copie mise à jour d'instructions).
- L'instruction TLB conserve des copies des entrées de table de pages (PTE). L'instruction de chaque cycle d'extraction a son adresse virtuelle traduit par ce TLB en une adresse physique. Chaque entrée est de 4 ou 8 octets en mémoire. Parce que le K8 a une taille variable de la page, chacun des TLB est divisé en deux sections, l'une pour garder PTE qui correspondent pages de 4 Ko, et l'un de garder PTE que la carte 4 Mo ou 2 Mo de pages. La scission permet le circuit de correspondance entièrement associative dans chaque section d'être plus simple. Le système d'exploitation maps différentes sections de l'espace d'adressage virtuel avec différentes PTE de taille.
- Les données TLB possède deux copies qui gardent les entrées identiques. Les deux exemplaires permettent de deux données accède par cycle pour traduire les adresses virtuelles en adresses physiques. Comme l'instruction TLB, ce TLB est divisé en deux types d'entrées.
- Le cache de données conserve des copies des lignes de 64 octets de mémoire. Il est divisé en 8 banques (chacun stocker 8 Ko de données), et peut aller chercher deux données de 8 octets chaque cycle tant que ces données sont dans différentes banques. Il ya deux copies des étiquettes, parce que chaque ligne de 64 octets est réparti entre tous les 8 banques. Chaque copie d'étiquette gère l'un des deux accès par cycle.
Le K8 a aussi des caches de niveau multiple. Il ya instructions et de données TLB de second niveau, qui stockent seulement PTE cartographie 4 ko. Les deux instructions et de données caches, et les divers TLB, peuvent remplir de la grande unifié cache L2. Ce cache est exclusif à la fois l'instruction de caches L1 et de données, ce qui signifie que toute ligne de 8 octets ne peut être dans l'un des cache L1 d'instruction, le cache de données L1, ou le cache L2. Il est, toutefois, possible pour une ligne dans le cache de données pour avoir une PTE qui est aussi dans l'un des-le TLB système d'exploitation est chargé de tenir les TLBs cohérentes par rinçage des portions de ceux où les tables de pages en mémoire sont mis à jour.
Le K8 met également en cache des informations qui ne sont jamais stockées dans la mémoire d'informations de prédiction. Ces caches ne sont pas représentés dans le schéma ci-dessus. Comme il est habituel pour cette classe de CPU, le K8 a assez complexe prédiction de branchement, avec des tables qui aident à prévoir si les succursales sont prises et d'autres tables qui prédisent les objectifs de branches et de sauts. Certaines de ces informations est associé à des instructions, à la fois dans la mémoire cache de niveau 1 d'instruction et le cache secondaire unifié.
Le K8 utilise un truc intéressant pour stocker des informations de prédiction avec des instructions dans le cache secondaire. Lignes dans le cache secondaire sont protégés contre la corruption accidentelle de données (par exemple, par une grève de la particule alpha) soit par ECC ou la parité, selon que ces lignes ont été expulsés de données ou des caches de l'instruction primaire. Puisque le code de parité prend moins de bits que le code ECC, les lignes de la mémoire cache d'instruction ont quelques bits de rechange. Ces bits sont utilisés pour mettre en cache l'information de prédiction de branche associée à ces instructions. Le résultat net est que le prédicteur de branchement a une plus grande table de l'histoire effective, et a donc une meilleure précision.
Plus de hiérarchies
Autres processeurs ont d'autres types de prédicteurs (par exemple, la dérivation prédicteur magasin à charge dans le Décembre Alpha 21264), et divers prédicteurs spécialisés sont susceptibles de prospérer dans les futurs processeurs.
Ces prédicteurs sont caches en ce qu'ils stockent des informations qui est coûteux à calculer. Une partie de la terminologie utilisée lors de l'examen des prédicteurs est la même que celle pour les caches (on parle d'un coup dans un prédicteur de branchement), mais ne sont pas prédictifs généralement considéré comme faisant partie de la hiérarchie de cache.
Le K8 garde les instructions et de données caches cohérentes dans le matériel, ce qui signifie que dans un magasin une instruction en suivant de près l'instruction de stockage va changer qu'à la suite de l'instruction. D'autres processeurs, comme ceux de la famille Alpha et MIPS, se sont appuyés sur le logiciel de garder le cache d'instruction cohérente. Magasins ne sont pas garantis à apparaître dans le courant de l'instruction jusqu'à ce qu'un programme appelle une installation de système d'exploitation pour assurer la cohérence.
Exécution
Cache lit sont le fonctionnement du processeur le plus commun qui prend plus d'un seul cycle. le temps d'exécution du programme a tendance à être très sensibles à la latence d'un cache de données hit niveau 1. Une grande partie de l'effort de conception, et de la puissance et de silicium souvent domaine sont dépensés rend les caches aussi vite que possible.
Le cache plus simple est un cache en correspondance directe pratiquement indexées. L'adresse virtuelle est calculée avec une vipère, la partie pertinente de l'adresse extraite et utilisée pour indexer une SRAM, qui renvoie les données chargées. L'octet de données est aligné dans un dispositif de décalage d'octet, et à partir de là est court-circuité à l'opération suivante. Il n'y a pas besoin de toute étiquette de vérifier dans la boucle intérieure - en fait, les balises ne devraient même pas être lus. Plus tard dans le pipeline, mais avant l'instruction de chargement est à la retraite, la balise pour les données chargées doit être lu et vérifié par rapport à l'adresse virtuelle pour vous assurer qu'il a été un succès de cache. Sur une miss, le cache est mis à jour avec la ligne de cache demandé et le pipeline est redémarré.
Un cache associatif est plus compliqué, car une certaine forme de balise doit être lue afin de déterminer quelle entrée de la mémoire cache pour sélectionner. Une N-way set-associative niveau 1 cache lit habituellement tous les N possibles balises et N données en parallèle, puis choisit les données associées à l'étiquette correspondante. caches de niveau-2 sauvent parfois la puissance en lisant les étiquettes d'abord, de sorte que un seul élément de données est lu à partir de la SRAM de données.

Le schéma de droite est destinée à clarifier la façon dont les divers champs de l'adresse sont utilisés. Le bit d'adresse 31 est le plus significatif, le bit 0 est le moins significatif. Le diagramme montre la SRAM, d'indexation et de multiplexage pour un 4 kB, 2-way set-associative, quasiment indexés et cache pratiquement balisé avec 64 lignes B, un 32b lire largeur et 32b adresse virtuelle.
Parce que le cache est de 4 ko et dispose de 64 lignes B, il n'y a que 64 lignes dans le cache, et nous lisons deux à la fois à partir d'une mémoire SRAM de Tag qui a 32 rangées, chacun avec une paire de 21 balises bits. Bien que toute fonction d'adresse virtuelle bits 31 à 6 pourrait être utilisé pour indexer le tag et SRAM de données, il est plus simple d'utiliser les bits les moins significatifs.
De même, parce que le cache est de 4 ko et dispose d'un chemin de lecture de 4 B, et lit deux manières pour chaque accès, la SRAM de données est de 512 lignes par 8 octets de large.
Un cache plus moderne pourrait être 16 ko, 4-way set-associative, pratiquement indexée, pratiquement laissé entendre, et physiquement marqué, avec 32 lignes B, 32b lire des adresses physiques largeur et 36b. La récurrence de chemin lire pour un tel cache est très similaire à la trajectoire ci-dessus. Au lieu de balises, vhints sont lues et comparées avec un sous-ensemble de l'adresse virtuelle. Plus tard dans le pipeline, l'adresse virtuelle est traduite en une adresse physique par le TLB, et l'étiquette physique est lu (une seule, comme les fournitures de vhint quel côté de la mémoire cache à lire). Enfin l'adresse physique est comparée à l'étiquette physique pour déterminer si un coup a eu lieu.
Certains modèles SPARC ont amélioré la vitesse de leurs caches L1 par quelques portes retards par l'effondrement de l'adresse additionneur virtuelle dans les décodeurs de SRAM. Voir Somme adressée décodeur.
Histoire
L'histoire des débuts de la technologie de cache est étroitement liée à l'invention et l'utilisation de la mémoire virtuelle. En raison de la rareté et le coût des semi-conducteurs mémoires, ordinateurs centraux début dans les années 1960 ont utilisé une hiérarchie complexe de la mémoire physique, mappé sur un espace de mémoire virtuelle plat utilisé par les programmes. Les technologies de mémoire seraient couvrir des semi-conducteurs, noyau magnétique, le tambour et disque. La mémoire virtuelle vu et utilisé par des programmes serait plat et la mise en cache serait utilisée pour récupérer les données et les instructions dans la mémoire plus rapide devant l'accès du processeur. Des études approfondies ont été effectuées pour optimiser les tailles de cache. Les valeurs optimales ont été trouvés à dépendre grandement sur le langage de programmation utilisé avec Algol besoin le plus petit et Fortran et Cobol besoin des plus grandes tailles de cache.
Dans les premiers jours de la technologie de micro-ordinateur, un accès mémoire était seulement légèrement plus lent que l'accès inscrire. Mais depuis les années 1980 l'écart de performance entre le processeur et la mémoire a été de plus en plus. Microprocesseurs ont progressé beaucoup plus vite que la mémoire, en particulier en termes de fonctionnement fréquence, de sorte que la mémoire est devenue une performance goulot d'étranglement. Alors qu'il était techniquement possible d'avoir toute la mémoire principale aussi rapide que le CPU, un chemin plus économiquement viable a été prise: utiliser beaucoup de mémoire à basse vitesse, mais aussi introduire une petite mémoire cache haute vitesse pour atténuer l'écart de performance. Cela a fourni un ordre de grandeur plus capacités pour le même prix avec seulement une performance combinée légèrement réduite.
Premières implémentations TLB
Les premières utilisations documentés d'un TLB étaient sur leGE645 et l'IBM 360/67, qui tous deux une mémoire associative utilisé comme un TLB.
Première cache de données
La première utilisation documentée d'un cache de données était sur leIBMModel 85 System / 360.
Dans microprocesseurs x86
Comme le microprocesseurs x86 atteint des taux de 20 MHz d'horloge et au-dessus de la 386, de petites quantités de mémoire cache rapide ont commencé à être présenté dans les systèmes pour améliorer les performances. Ce fut parce que la DRAM utilisée pour la mémoire principale avait une latence importante, jusqu'à 120 ns, ainsi que des cycles de rafraîchissement. La cache a été construit à partir de plus cher, mais nettement plus rapide, SRAM, qui à l'époque avait latences environ 10 ns. Les premières caches étaient externe au processeur et généralement situé sur la carte mère sous la forme de huit ou neuf dispositifs DIP placés en prises pour permettre le cache en option ou la fonctionnalité de mise à niveau.
Certaines versions du processeur Intel 386 pourraient appuyer de 16 à 64Ko de cache externe.
Avec le Processeur 486, une mémoire cache de 8 kB a été intégré directement dans la filière de la CPU. Cette cache a été appelé Niveau 1 ou cache L1 pour la différencier de la plus lente sur la carte mère, ou de niveau 2 (L2). Ces caches-mère étaient beaucoup plus grandes, avec la taille la plus courante étant 256 kB. La popularité de cache sur la carte mère a continué à travers l' ère Pentium MMX, mais a été rendue obsolète par l'introduction de SDRAM et la disparité croissante entre les taux d'horloge de bus et des fréquences d'horloge du processeur, ce qui a provoqué cache sur la carte mère pour être seulement légèrement plus rapide que la mémoire principale .
Le prochain développement dans la mise en œuvre de cache dans les microprocesseurs x86 a commencé avec lePentium Pro, qui a porté le cache secondaire sur le même package que le microprocesseur, cadencé à la même fréquence que le microprocesseur.
Sur la carte mère caches joui d'une popularité prolongées grâce aux AMD K6-2 et processeurs AMD K6-III qui utilisaient encore le vénérable Socket 7, qui a été précédemment utilisé par Intel avec des caches sur la carte mère. K6-III inclus 256 kb sur-die cache L2 et a profité de la cache à bord comme un cache de troisième niveau, nommé L3 (cartes mères avec un maximum de 2 Mo de cache à bord ont été produites). Après le Socket-7 est devenu obsolète, cache sur la carte mère a disparu des systèmes x86.
Le cache à trois niveaux a été utilisé à nouveau avec le premier introduction de plusieurs noyaux de processeur, où la L3 a été ajouté à la matrice de l'unité centrale. Il est devenu courant d'avoir les trois niveaux soient plus grande taille que la prochaine et, aujourd'hui, il est pas rare de trouver de niveau 3 tailles de cache de huit mégaoctets. Cette tendance semble se poursuivre dans un avenir prévisible.
La recherche actuelle
Design cache début concentre entièrement sur le coût direct de cache et la RAM et la vitesse d'exécution moyenne. Plus de conceptions de cache récentes considèrent également l'efficacité énergétique, la tolérance de panne, et d'autres objectifs.
Il existe plusieurs outils disponibles pour les architectes informatiques pour aider à explorer les compromis entre le cycle de cache temps, d'énergie, et de la zone. Ces outils comprennent l'open-source simulateur de mémoire cache de cactus et l'open-source instruction SimpleScalar ensemble simulateur.
Cache multi-accès
Un cache multi-accès est un cache qui peut servir plus d'une demande à la fois. En accédant à un cache traditionnelle, nous utilisons normalement une adresse mémoire unique, alors que dans un cache multi-accès, nous pouvons demander N adresses à la fois - où N est le nombre de ports reliés par le processeur et la mémoire cache. L'avantage de ceci est que un processeur en pipeline peut accéder à la mémoire à partir de différentes phases de son pipeline. Un autre avantage est qu'il permet le concept de processeurs super-scalaires à travers les niveaux de cache différentes.