

Unité centrale de traitement
À propos de ce écoles sélection Wikipedia
SOS Enfants a fait cette sélection Wikipedia aux côtés d'autres écoles des ressources . Le parrainage d'enfants aide les enfants un par un http://www.sponsor-a-child.org.uk/ .


Une unité centrale de traitement (CPU), également appelée une unité de processeur central, le matériel est l'intérieur d'un ordinateur qui exécute le des instructions d'un Programme d'ordinateur en effectuant la base arithmétique, logique, et opérations du système d'entrée / sortie. Le terme a été utilisé dans l'industrie informatique depuis au moins le début des années 1960. La forme, la conception et la mise en œuvre de processeurs ont changé au cours de leur histoire, mais leur opération fondamentale reste la même.
Dans les vieux ordinateurs, processeurs nécessitent une ou plusieurs les cartes de circuits imprimés. Avec l'invention de la microprocesseur, un processeur peut être contenue dans une seule puce de silicium . Les premiers ordinateurs à utiliser les microprocesseurs étaient ordinateurs personnels et de petits postes de travail. Depuis les années 1970 la classe microprocesseur de CPU a presque complètement dépassé toutes les autres mises en oeuvre de la CPU, dans la mesure où même ordinateurs centraux utilisent un ou plusieurs microprocesseurs. Les microprocesseurs modernes sont à grande échelle des circuits intégrés en paquets habituellement moins de quatre centimètres carrés, avec des centaines de broches de connexion.
Un ordinateur peut avoir plus d'un CPU; cela se appelle multitraitement. Certains microprocesseurs peuvent contenir plusieurs processeurs sur une seule puce; ces microprocesseurs sont appelés processeurs multi-core.
Deux composants typiques d'une CPU sont les unité arithmétique logique (ALU), qui effectue des opérations arithmétiques et logiques, et la unité de commande (CU), qui extrait des instructions à partir de mémoire et décode et les exécute, appelant le ALU lorsque cela est nécessaire.
Tous les systèmes informatiques se appuient sur une unité centrale de traitement. Un processeur de tableau ou processeur vectoriel comporte plusieurs éléments de calcul parallèle, sans une unité considéré comme le «centre». Dans le modèle de calcul distribué, les problèmes sont résolus par un ensemble interconnecté distribué de processeurs.
Histoire

Les ordinateurs tels que la ENIAC a dû être refaite physiquement d'effectuer différentes tâches, qui ont causé ces machines d'être appelés «ordinateurs-programme fixe." Comme le terme "CPU" est généralement défini comme un dispositif de logiciel (programme informatique) de l'exécution, les premiers dispositifs qui pourraient à juste titre être appelés CPU est venu avec l'avènement de la ordinateur à programme enregistré.
L'idée d'un ordinateur à programme enregistré était déjà présente dans la conception de J. Eckert et Presper John William Mauchly de ENIAC, mais a été omise initialement afin qu'il puisse être terminée plus tôt. Le 30 Juin 1945, avant d'ENIAC a été faite, mathématicien John von Neumann a distribué le document intitulé Première ébauche d'un rapport sur la EDVAC. Ce était le contour d'un ordinateur à programme enregistré qui serait finalement achevée en Août 1949. EDVAC a été conçu pour effectuer un certain nombre d'instructions (ou des opérations) de divers types. Ces instructions pourraient être combinées pour créer des programmes utiles pour la EDVAC à exécuter. De manière significative, les programmes écrits pour EDVAC ont été stockés à grande vitesse mémoire d'ordinateur plutôt que spécifié par le câblage physique de l'ordinateur. Ce surmonté une limitation sévère de ENIAC, qui était le temps et les efforts nécessaires pour reconfigurer l'ordinateur pour effectuer une nouvelle tâche. Avec la conception, le programme, ou un logiciel de von Neumann, qui EDVAC reçoit pourrait être changé simplement en changeant le contenu de la mémoire.
Les premiers processeurs ont été conçus sur mesure comme une partie d'un plus grand, parfois one-of-a-kind, ordinateur. Cependant, cette méthode de conception de processeurs personnalisés pour une application particulière a largement cédé la place au développement des processeurs de série qui sont faites à de nombreuses fins. Cette normalisation a commencé à l'époque de discrète transistor mainframes et mini-ordinateurs et a rapidement accéléré avec la popularisation du circuit intégré (IC). L'IC a permis processeurs de plus en plus complexes pour être conçus et fabriqués à des tolérances de l'ordre de nanomètres. Tant la miniaturisation et la normalisation de processeurs ont augmenté la présence des appareils numériques dans la vie moderne au-delà de l'application limitée des machines informatiques dédiés. Les microprocesseurs modernes apparaissent dans tout, des voitures aux téléphones portables et les jouets pour enfants.
Alors que von Neumann est le plus souvent crédité de la conception de l'ordinateur à programme enregistré en raison de sa conception de EDVAC, d'autres avant lui, comme Konrad Zuse, avait suggéré et mis en œuvre des idées similaires. La dite L'architecture de la Harvard Harvard Mark I, qui a été achevée avant EDVAC, également utilisé une conception à programme enregistré à l'aide bande de papier perforé plutôt que la mémoire électronique. La principale différence entre les architectures de von Neumann et Harvard est que celui-ci sépare le stockage et le traitement des instructions et des données CPU, tandis que le premier utilise le même espace mémoire pour les deux. La plupart des processeurs modernes sont principalement von Neumann dans la conception, mais des éléments de l'architecture de Harvard sont généralement vus ainsi.
Relais et tubes à vide (soupapes thermioniques) ont été couramment utilisés comme éléments de commutation; un ordinateur utile exige des milliers ou des dizaines de milliers de dispositifs de commutation. La vitesse globale du système est fonction de la vitesse des commutateurs. Tube comme ordinateurs EDVAC tendance à moyenne huit heures entre les pannes, tandis que les ordinateurs de relais (comme le plus lent, mais plus tôt) Harvard Mark I n'a que très rarement. En fin de compte, les processeurs à base de tubes devenus dominants parce que les avantages significatifs de la vitesse offertes généralement l'emportent sur les problèmes de fiabilité. La plupart de ces processeurs synchrones début couru à basse taux d'horloge par rapport aux conceptions microélectroniques modernes (voir ci-dessous pour une discussion de fréquence d'horloge). les fréquences de signal d'horloge allant de 100 kHz à 4 MHz ont été très fréquents à cette époque, largement limitée par la vitesse des dispositifs de commutation ils ont été construits avec.
Transistor et les processeurs de circuits intégrés

La complexité de la conception de CPU a augmenté aussi diverses technologies ont facilité la construction d'appareils plus petits et plus fiables. La première amélioration est venue avec l'avènement de la transistor. CPU à transistors au cours des années 1950 et 1960 ne avaient plus à être construit à partir d'éléments de commutation encombrants, fiables, et fragiles comme des tubes à vide et relais électriques. Avec cette amélioration processeurs plus complexes et fiables ont été construits sur une ou plusieurs cartes de circuits imprimés contenant (individuels) composants discrets.
Pendant cette période, un procédé de fabrication de transistors interconnectés dans un espace compact a été développé. Le circuit intégré (IC) a permis à un grand nombre de transistors à fabriquer sur une seule semi-conducteur à base de mourir, ou «puce». Au premiers circuits numériques non spécialisés que très de base tels que NOR portes ont été miniaturisés en CI. Processeurs basés sur ces circuits "blocs de construction" sont généralement désignés comme des dispositifs (SSI) "intégration à petite échelle". CI SSI, tels que ceux utilisés dans la Apollo ordinateur de guidage, généralement contenait jusqu'à quelques transistors de pointage. Pour construire tout un CPU sur SSI CI nécessaire des milliers de puces individuelles, mais toujours consommé beaucoup moins d'espace et de puissance que les anciens modèles de transistors discrets. Comme la technologie microélectronique avancée, un nombre croissant de transistors ont été placés sur les circuits intégrés, diminuant ainsi la quantité de circuits individuels nécessaires pour une CPU complète. MSI et LSI (intégration à moyenne et grande échelle) des circuits intégrés ont augmenté du nombre de transistors à des centaines, puis des milliers.
En 1964, IBM a présenté son System / 360 de l'architecture de l'ordinateur qui a été utilisé dans une série d'ordinateurs pouvant exécuter des programmes avec les mêmes vitesse et des performances différentes. Ce était important à un moment où la plupart des ordinateurs électroniques étaient incompatibles avec une autre, même celles faites par le même fabricant. Pour faciliter cette amélioration, IBM a utilisé le concept de microprogramme (souvent appelé "microcode"), qui voit encore l'utilisation répandue dans les processeurs modernes. Le système / 360 l'architecture était si populaire qu'il a dominé la marché de l'informatique mainframe depuis des décennies et a laissé un héritage qui est toujours poursuivi par les ordinateurs modernes similaires, comme l'IBM zSeries. Dans la même année (1964), Digital Equipment Corporation (DEC) a introduit un autre ordinateur influente visant à les marchés scientifiques et de recherche, le PDP-8. Décembre plus tard présenter le très populaire PDP-11 ligne qui a été à l'origine construit avec SSI CI, mais a finalement été mis en œuvre avec des composants LSI fois ci sont devenus pratique. En contraste avec ses prédécesseurs SSI et MSI, la première mise en œuvre de la LSI PDP-11 contenait un CPU composé de seulement quatre circuits intégrés LSI.
Ordinateurs à base de transistors ont plusieurs avantages distincts par rapport à leurs prédécesseurs. En dehors de faciliter une fiabilité accrue et une faible consommation électrique, les transistors ont également permis CPU de fonctionner à des vitesses beaucoup plus élevées en raison du temps de commutation d'un transistor court par rapport à un tube ou un relais. Merci à la fois la fiabilité accrue ainsi que la vitesse considérablement accrue des éléments de commutation (qui étaient presque exclusivement des transistors à cette époque), les taux d'horloge du processeur dans les dizaines de mégahertz ont été obtenus au cours de cette période. En outre tandis que le transistor discret et IC CPU étaient en usage intensif, nouvelle haute performance conçoit comme SIMD (Single Instruction Multiple Data) processeurs vectoriels ont commencé à apparaître. Ces modèles expérimentaux début ont donné plus tard naissance à l'ère de la spécialisée supercalculateurs comme celles faites par Cray Inc.
Microprocesseurs


Dans les années 1970, les inventions fondamentales par Federico Faggin (ci Silicon grille MOS avec auto alignée portes ainsi que sa nouvelle méthodologie de conception logique aléatoire) a changé la conception et la mise en œuvre de processeurs toujours. Depuis l'introduction du premier microprocesseur disponible dans le commerce (le Intel 4004) en 1970, et le premier largement utilisé microprocesseur (le Intel 8080) en 1974, cette classe de processeurs a presque complètement dépassé toutes les autres méthodes de mise en œuvre de l'unité centrale de traitement. Mainframe et mini-ordinateurs de l'époque fabricants ont lancé des programmes exclusifs de développement de circuits intégrés pour mettre à jour leur plus architectures informatiques, et éventuellement produits jeu d'instructions microprocesseurs compatibles qui étaient en arrière-compatible avec leur matériel plus ancien et le logiciel. Combiné avec l'avènement et le succès éventuel de l'omniprésent ordinateur personnel , la CPU terme est maintenant appliqué presque exclusivement aux microprocesseurs. Plusieurs processeurs peuvent être combinés dans une seule puce de traitement.
Les générations précédentes de processeurs ont été mises en œuvre comme des composants discrets et de nombreux petits circuits intégrés (CI) sur une ou plusieurs cartes de circuits. Microprocesseurs, d'autre part, sont fabriqués CPU sur un très petit nombre de circuits intégrés; généralement un seul. La taille globale de CPU plus petite à la suite d'être mis en œuvre sur une seule puce désigne le temps de commutation plus rapide en raison de facteurs physiques comme la porte a diminué capacité parasite. Cela a permis microprocesseurs synchrones à avoir des taux d'horloge allant de quelques dizaines de mégahertz à plusieurs gigahertz. En outre, comme la capacité de construire excessivement petits transistors sur un circuit intégré a augmenté, la complexité et le nombre de transistors dans un seul processeur a augmenté de plusieurs fois. Cette tendance largement observée est décrit par la loi de Moore , qui se est avéré être un prédicteur assez précise de la croissance de la CPU (et d'autres IC) la complexité.
Bien que la complexité, la taille, la construction, et la forme générale de CPU ont énormément changé depuis 1950, il est à noter que la conception et la fonction de base n'a pas beaucoup changé du tout. Presque toutes les CPU courante aujourd'hui peut être décrit très précisément que von Neumann machines-programme stocké. Comme la loi de Moore précitée continue à être vrai, des préoccupations ont été soulevées au sujet des limites de la technologie intégrée à transistor de circuit. Miniaturisation extrême de portes électroniques est à l'origine des effets de phénomènes comme électromigration et une fuite sous le seuil pour devenir beaucoup plus important. Ces préoccupations plus récentes sont parmi les nombreux facteurs qui causent les chercheurs à étudier de nouvelles méthodes de calcul tels que l' ordinateur quantique , ainsi que d'étendre l'utilisation de parallélisme et d'autres méthodes qui se étendent l'utilité du modèle de von Neumann classique.
Opération
L'opération fondamentale de la plupart des processeurs, indépendamment de la forme physique, ils prennent, est d'exécuter une séquence d'instructions stockées appelées un programme. Le programme est représenté par une série de nombres qui sont conservées dans une sorte de mémoire d'ordinateur. Il ya quatre étapes que presque tous les processeurs utilisent dans leur fonctionnement: chercher, décodage, exécution et écriture différée.
La première étape, chercher, implique la récupération d'un instruction (qui est représenté par un numéro ou une séquence de nombres) de la mémoire de programme. L'emplacement dans la mémoire de programme est déterminé par un compteur de programme (PC), qui mémorise un numéro qui identifie la position actuelle dans le programme. Après une instruction est extraite, le PC est incrémentée de la longueur du mot d'instruction en termes d'unités de mémoire. Souvent, l'instruction à extraire doit être extrait de la mémoire relativement lente, ce qui provoque la CPU pour bloquer en attendant l'instruction à renvoyer. Cette question est largement traitée dans les processeurs modernes par des caches et des architectures de pipelines (voir ci-dessous).
L'instruction que le CPU récupère de la mémoire est utilisée pour déterminer ce que le CPU est à faire. Dans l'étape de décodage, l'instruction est divisé en parties qui ont une importance pour d'autres parties de la CPU. La façon dont la valeur d'instruction est interprétée numérique est définie par le jeu d'instructions de l'architecture du CPU (ISA). Souvent, un groupe de numéros dans l'instruction, appelée code d'opération, ce qui indique l'opération à effectuer. Les parties restantes du nombre fournissent généralement des informations nécessaires à cette instruction, comme opérandes pour une opération d'addition. Ces opérandes peuvent être donnés comme une valeur constante (appelée une valeur immédiate), ou comme un emplacement pour une valeur: un se inscrire ou une adresse mémoire, tel que déterminé par un certain mode d'adressage. Dans les conceptions anciennes parties de la CPU responsable de décodage d'instruction sont des dispositifs matériels immuables. Cependant, dans les CPU et des ISA plus abstrait et complexe, un microprogramme est souvent utilisée pour aider à traduire des instructions dans différents signaux de configuration de la CPU. Ce microprogramme est parfois réinscriptible de sorte qu'il peut être modifié pour changer la façon dont le CPU décode instructions, même après qu'il a été fabriqué.
Après les étapes récupérer et décoder, exécuter l'étape est effectuée. Au cours de cette étape, différentes parties de la CPU sont connectés afin qu'ils puissent effectuer l'opération souhaitée. Si, par exemple, une opération d'addition a été demandée, la Unité arithmétique et logique (ALU) est reliée à un ensemble d'entrées et un ensemble de sorties. Les entrées fournissent les nombres à additionner, et les sorties contiennent la somme finale. L'ALU contient les circuits nécessaires pour effectuer de simples opérations arithmétiques et logiques sur les entrées (comme l'addition et opérations bit à bit). Si l'opération d'addition donne un résultat trop grand pour le CPU à manipuler, un drapeau de débordement arithmétique dans un registre de drapeaux peuvent également être réglé.
La dernière étape, réécriture, tout simplement », écrit back" les résultats de l'étape d'exécuter une certaine forme de mémoire. Très souvent, les résultats sont écrits dans une certaine registre de CPU interne pour un accès rapide par des instructions ultérieures. Dans d'autres cas, les résultats peuvent être écrites plus lent, mais moins cher et plus grand, mémoire principale. Certains types de manipuler instructions du compteur de programme au lieu de produire directement des données de résultat. Ils sont généralement appelés «sauts» et facilitent un tel comportement boucles, l'exécution du programme conditionnelle (grâce à l'utilisation d'un saut conditionnel), et les fonctions de programmes. Beaucoup instructions seront également changer l'état de chiffres dans un registre "flags". Ces drapeaux peuvent être utilisés pour influencer la façon dont un programme se comporte, car ils indiquent souvent le résultat des différentes opérations. Par exemple, un type de "comparer" instruction considère deux valeurs et fixe un certain nombre dans les drapeaux registre selon laquelle est supérieure. Cet indicateur pourrait alors être utilisé par une instruction de saut plus tard pour déterminer le déroulement du programme.
Après l'exécution de l'instruction et de réécriture des données résultantes, l'ensemble du processus se répète, avec le prochain cycle d'instruction normalement aller chercher l'instruction suivante en séquence en raison de la valeur incrémentée dans le compteur de programme. Si l'instruction était terminée un saut, le compteur de programme sera modifié pour contenir l'adresse de l'instruction qui a été passé à, et l'exécution du programme se poursuit normalement. Dans processeurs plus complexe que celle décrite ici, plusieurs instructions peuvent être récupérés, décodé, et exécuté simultanément. Cette section décrit ce qui est généralement désigné sous le nom " RISC classique pipeline », qui est en fait assez fréquent chez les processeurs simples utilisés dans de nombreux appareils électroniques (souvent appelé microcontrôleur). Il ignore largement le rôle important du cache du processeur , et donc le niveau de la filière d'accès.
Conception et mise en œuvre
Le concept de base d'un processeur est la suivante:
Câblé dans la conception d'un CPU est une liste des opérations de base qu'il peut effectuer, appelé jeu d'instructions. Ces opérations peuvent inclure l'ajout ou la soustraction de deux nombres, la comparaison des nombres, ou sauter dans une autre partie d'un programme. Chacune de ces opérations de base est représenté par une séquence particulière de bits; cette séquence est appelée opcode pour cette opération particulière. Envoi d'un opcode particulier à une CPU amener à effectuer l'opération représentée par ledit code opération. Pour exécuter une instruction dans un programme d'ordinateur, le processeur utilise le code opération de cette instruction ainsi que ses arguments (par exemple, les deux nombres à additionner, dans le cas d'une opération d'addition). Un programme d'ordinateur est donc une séquence d'instructions, à chaque instruction, y compris un opcode et les arguments de cette opération.
L'opération mathématique réelle de chaque instruction est effectuée par une sous-unité de la CPU connu sous le nom Unité arithmétique et logique ou ALU. En plus d'utiliser son ALU pour exécuter des opérations, une unité centrale est également responsable de la lecture de l'instruction suivante à partir de la mémoire, la lecture des données spécifiées dans les arguments de la mémoire, et écrire les résultats en mémoire.
Dans de nombreux modèles de CPU, un jeu d'instructions sera clairement la distinction entre les opérations que les données de charge de la mémoire, et de ceux qui effectuent les mathématiques. Dans ce cas, les données chargées dans la mémoire sont stockées dans registres, et une opération mathématique ne prend aucun argument, mais effectue tout simplement le calcul sur les données dans les registres et l'écrit dans un nouveau registre, dont la valeur d'une opération distincte peut alors écrire dans la mémoire.
Unité de contrôle
L'unité de l'unité centrale de commande contient un circuit qui utilise des signaux électriques pour diriger le système informatique à exécuter des instructions de programme mémorisées. L'unité de commande ne exécute pas d'instructions de programme; plutôt, réalise d'autres parties du système pour le faire. L'unité de contrôle doit communiquer à la fois avec le / unité et la mémoire arithmétique et logique.
Gamme Entier
La manière dont un CPU représente des nombres est un choix de conception qui affecte les moyens les plus élémentaires dans lesquels des fonctions de l'appareil. Certains ordinateurs numériques premiers ont utilisé un modèle électrique de la commune décimal (de base dix) système numérique pour représenter des nombres en interne. Quelques autres ordinateurs ont utilisé des systèmes numériques plus exotiques comme ternaire (base de trois). Presque tous les processeurs modernes représentent des nombres en binaire forme, avec chaque chiffre étant représenté par une certaine quantité physique à deux valeurs telles que «haut» ou «bas» tension .

Liées à la représentation de nombre est la taille et la précision des chiffres qu'une CPU peut représenter. Dans le cas d'une CPU binaire, un peu fait référence à une place importante dans les numéros un processeur traite. Le nombre de bits (ou des lieux numériques) un processeur utilise pour représenter des nombres est souvent appelé " taille de mot "," largeur de bit "," largeur de chemin de données "ou" précision entière "lorsqu'il se agit de nombres entiers strictement (par opposition à point flottant). Ce nombre varie selon les architectures, et souvent dans différentes parties de la même CPU. Par exemple, un 8 bits CPU traite une plage de numéros pouvant être représentée par huit chiffres binaires (chaque chiffre ayant deux valeurs possibles), ce est-2 8 ou 256 nombres discrets. En effet, la taille entier fixe une limite de matériel sur la plage de nombres entiers du logiciel exécuté par le CPU peut utiliser.
Entier gamme peut également affecter le nombre d'emplacements dans la mémoire du CPU peut résoudre (localiser). Par exemple, si un CPU binaire utilise 32 bits pour représenter une adresse de mémoire, et chaque adresse de mémoire représente une octet (8 bits), la quantité maximale de mémoire CPU peut traiter est de 2 32 octets, soit 4 Gio. Ce est une vue très simple de CPU l'espace d'adressage, et de nombreux modèles utilisent des méthodes d'adressage plus complexes comme paging pour localiser plus de mémoire que leur gamme entière permettrait avec un espace d'adressage plat.
Des niveaux plus élevés de gamme entier exigent plus de structures pour traiter les chiffres supplémentaires, et donc plus de complexité, la taille, la consommation d'énergie et les frais généraux. Il ne est pas du tout rare, par conséquent, voir 4 ou 8 bits microcontrôleurs utilisés dans des applications modernes, même si les CPU avec la gamme beaucoup plus élevé (comme 16, 32, 64, même 128 bits) sont disponibles. Les microcontrôleurs simples sont généralement moins chers, consomment moins d'énergie, et donc génèrent moins de chaleur, qui peuvent tous être des considérations de conception pour les appareils électroniques. Cependant, dans les applications haut de gamme, les avantages offerts par la gamme supplémentaire (le plus souvent l'espace d'adressage supplémentaires) sont plus importants et souvent influent sur les choix de conception. Pour obtenir certains des avantages procurés par les deux longueurs de bit inférieur et supérieur, de nombreux processeurs sont conçus avec des largeurs de bits différentes pour différentes parties du dispositif. Par exemple, le IBM System / 370 utilise un CPU qui est principalement 32 bits, mais il utilise la précision de 128 bits intérieur de son unités de virgule flottante pour faciliter une plus grande précision et la gamme de nombres à virgule flottante. Beaucoup de conceptions de processeur ultérieures utilisent largeur similaire de peu mitigées, en particulier lorsque le processeur est conçu pour une utilisation polyvalente où un équilibre raisonnable entre entiers et flottants capacité de point est nécessaire.
Fréquence d'horloge
La fréquence d'horloge est la vitesse à laquelle un microprocesseur exécute les instructions. Chaque ordinateur contient une horloge interne qui régule la vitesse à laquelle les instructions sont exécutées et synchronise tous les différents composants de l'ordinateur. La CPU a besoin d'un nombre fixe de tops d'horloge (ou de cycles d'horloge) pour exécuter chaque instruction. Le plus rapide de l'horloge, plus les instructions du CPU peut exécuter par seconde.
La plupart des CPU, et même plus dispositifs séquentiels logiques, sont synchrone dans la nature. Autrement dit, ils sont conçus et fonctionnent sur des hypothèses concernant un signal de synchronisation. Ce signal, appelé signal d'horloge, prend généralement la forme d'un périodique onde carrée. En calculant le temps maximum que les signaux électriques peuvent se déplacer dans les différentes branches de nombreux circuits d'un CPU, les concepteurs peuvent choisir une appropriée période du signal d'horloge.
Cette période doit être supérieure à la quantité de temps qu'il faut pour un signal de se déplacer, ou propager, dans le pire des cas. En fixant la période d'horloge à une valeur bien supérieure à la pire temps de propagation, il est possible de concevoir l'ensemble de la CPU et la façon dont elle se déplace autour des données "bords" du signal d'horloge montant et descendant. Cela a l'avantage de simplifier sensiblement la CPU, à la fois du point de vue de la conception et une perspective composante de comptage. Toutefois, elle comporte aussi l'inconvénient que l'ensemble de la CPU doit attendre sur ses éléments les plus lents, même si certaines parties de celui-ci sont beaucoup plus rapides. Cette limitation a été largement compensée par diverses méthodes d'augmentation CPU parallélisme. (Voir ci-dessous)
Cependant, des améliorations architecturales seules ne résolvent pas tous les inconvénients de processeurs synchrones à l'échelle mondiale. Par exemple, un signal d'horloge est soumis à des retards de tout autre signal électrique. Des fréquences d'horloge plus élevées dans les processeurs de plus en plus complexes, il est plus difficile de garder le signal d'horloge en phase (synchronisée) dans l'ensemble de l'unité. Cela a conduit de nombreux processeurs modernes d'exiger de multiples signaux d'horloge identique à fournir pour éviter de retarder un seul signal suffisamment pour provoquer la CPU à un dysfonctionnement. Un autre problème majeur que les taux d'horloge est augmentent considérablement la quantité de chaleur qui est dissipée par la CPU. L'horloge en constante évolution provoque de nombreux composants pour basculer indépendamment du fait qu'ils sont utilisés à l'époque. En général, un composant de commutation qui utilise plus d'énergie qu'un élément dans un état statique. Par conséquent, les hausses de taux d'horloge, il en va de la consommation d'énergie, provoquant la CPU à exiger plus la dissipation de chaleur sous la forme de solutions de refroidissement de CPU.
Une méthode de traiter avec la commutation des composants inutiles est appelé horloge de déclenchement, qui consiste à éteindre le signal d'horloge aux composants inutiles (en fait, de les désactiver). Cependant, ce est souvent considérée comme difficile à mettre en œuvre et donc ne voit pas l'usage commun en dehors des mêmes modèles de faible puissance. Une conception remarquable fin de CPU qui utilise clock gating pour réduire les besoins en énergie de la console de jeu vidéo est celle de l'IBM PowerPC Xbox 360. Il utilise une vaste ouverture de porte d'horloge dans lequel il est utilisé. Un autre procédé pour résoudre certains des problèmes avec un signal d'horloge global est la suppression du signal d'horloge tout à fait. Avantages tout en enlevant le signal d'horloge global rend le processus de conception beaucoup plus complexe à bien des égards, asynchrone (sans horloge ou) conçoit transportent marquée de la consommation d'énergie et dissipation de la chaleur en comparaison avec des conceptions synchrones similaires. Bien que peu commun, ensemble processeurs asynchrones ont été construits sans utiliser un signal d'horloge global. Deux exemples notables de ce sont les ARM compatible AMULETTE et MiniMips compatibles MIPS R3000. Plutôt que de retirer totalement le signal d'horloge, certains modèles de CPU permettent certaines parties de l'appareil à être asynchrone, comme l'utilisation asynchrone UMM en conjonction avec pipeline superscalaire pour obtenir des gains de performance arithmétiques. Alors que ce ne est pas tout à fait clair si totalement conceptions asynchrones peuvent effectuer à un niveau comparable ou mieux que leurs homologues synchrones, il est évident qu'ils ne excellent au moins dans les opérations mathématiques simples. Ceci, combiné avec leurs excellentes consommation d'énergie et de chaleur propriétés de dissipation, les rend très approprié pour calculateurs embarqués.
Parallélisme
La description du fonctionnement de base d'un CPU offert dans la section précédente décrit la forme la plus simple qu'une CPU peut prendre. Ce type de CPU, habituellement dénommé subscalar, et opère sur une instruction se exécute sur un ou deux éléments de données à la fois.
Ce processus donne lieu à une inefficacité inhérente à processeurs subscalar. Étant donné que seule une instruction est exécutée à la fois, l'ensemble de la CPU doit attendre que l'instruction soit terminée avant de passer à l'instruction suivante. Par conséquent, la CPU se subscalar "raccroché" sur instructions qui ont plus d'un cycle d'horloge pour terminer l'exécution. Même l'addition d'un second unité d'exécution (voir ci-dessous) ne améliore pas les performances beaucoup; plutôt qu'une voie étant raccroché, maintenant deux voies sont suspendus et le nombre de transistors non utilisés est augmenté. Cette conception, dans laquelle les ressources d'exécution de la CPU peuvent fonctionner sur une seule instruction à la fois, ne peut éventuellement atteindre la performance scalaire (une d'instructions par cycle d'horloge). Cependant, le rendement est presque toujours subscalar (moins d'une instruction par cycle).
Les tentatives visant à atteindre une meilleure performance scalaire et ont abouti à une variété de méthodologies de conception qui font que le CPU se comporter moins linéaire et plus en parallèle. Lorsqu'on se réfère à un parallélisme dans les CPU, deux termes sont généralement utilisés pour classer ces techniques de conception. niveau de parallélisme d'instructions (ILP) vise à accroître la vitesse à laquelle les instructions sont exécutées dans un CPU (ce est d'augmenter l'utilisation des ressources sur-die l'exécution), et parallélisme au niveau de fil (TLP) fins d'augmenter le nombre de (fils efficacement les programmes individuels) qu'un processeur peut exécuter simultanément. Chaque méthodologie diffère à la fois dans la manière dont ils sont mis en œuvre, ainsi que l'efficacité relative qu'elles accordent à accroître la performance du CPU pour une application.
parallélisme d'instruction

Une des méthodes les plus simples utilisés pour accomplir un parallélisme accru est de commencer les premières étapes de l'instruction extraire et décoder avant l'instruction avant fin de l'exécution. Ce est la forme la plus simple d'une technique connue sous le nom instruction pipeline, et est utilisé dans presque tous les processeurs à usage général modernes. Pipelining permet plus d'une instruction à exécuter à un moment donné en brisant la voie d'exécution en étapes discrètes. Cette séparation peut être comparée à une chaîne de montage, dans lequel une instruction est rendue plus complète à chaque étape jusqu'à ce qu'il quitte le pipeline d'exécution et est retiré.
Pipeline ne, cependant, introduire la possibilité pour une situation où le résultat de l'opération précédente est nécessaire pour effectuer l'opération suivante; une condition appelée souvent dépendance de données conflit. Pour faire face à cela, des soins supplémentaires doivent être prises pour vérifier ces sortes de conditions et de retarder une partie de la pipeline d'instructions si cela se produit. Naturellement, ceci nécessite la réalisation de circuits supplémentaires, de sorte que les processeurs en pipeline sont plus complexes que ceux subscalar (mais pas de façon très significative). Un processeur pipeline peut devenir très près scalaire, inhibée seulement par des stands de pipeline (une instruction dépenser plus d'un cycle d'horloge dans un stade).
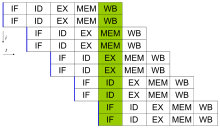
Poursuite de l'amélioration sur l'idée d'instruction pipeline conduit à l'élaboration d'une méthode qui diminue le temps d'inactivité de composants CPU encore plus loin. Designs qui sont censés être superscalaire comprennent un pipeline d'instruction longue et plusieurs unités d'exécution identiques. Dans un pipeline superscalaire, plusieurs instructions sont lues et transmises à un répartiteur, qui décide si oui ou non les instructions peuvent être exécutées en parallèle (simultanément). Si oui, ils sont envoyés à unités d'exécution disponibles, résultant dans la capacité pour plusieurs instructions soient exécutées simultanément. En général, plus un processeur superscalaire instructions est capable d'envoyer simultanément attente unités d'exécution, les instructions seront plus effectuées dans un cycle donné.
La plupart de la difficulté dans la conception d'une architecture de processeur superscalaire réside dans la création d'un répartiteur efficace. Le répartiteur doit être en mesure de déterminer rapidement et correctement si les instructions peuvent être exécutées en parallèle, ainsi que les dépêcher dans une manière de garder autant d'unités d'exécution occupés que possible. Il faut pour cela que le pipeline d'instructions est rempli le plus souvent possible et donne lieu à la nécessité, dans les architectures superscalaires pour des quantités significatives de mémoire cache de l'unité centrale . Il fait également des techniques de danger-en évitant comme la prédiction de branchement, exécution spéculative, et out-of-order exécution cruciale pour maintenir des niveaux élevés de performance. En tentant de prédire quelle branche (ou le chemin) une instruction conditionnelle prendra, le CPU peut minimiser le nombre de fois que l'ensemble du pipeline doit attendre une instruction conditionnelle est terminée. Exécution spéculative fournit souvent des performances modestes augmentations en exécutant des portions de code qui peuvent ne pas être nécessaire après une opération conditionnelle complète. Out-of-order exécution réorganise un peu l'ordre dans lequel les instructions sont exécutées afin de réduire les retards dus aux dépendances de données. Aussi en cas d'instructions simples de données multiples - un cas où un grand nombre de données à partir du même type doit être traitée, les processeurs modernes peuvent désactiver des parties de la canalisation de sorte que quand une seule instruction est exécutée à plusieurs reprises, la CPU saute le chercher et décoder phases et augmente ainsi considérablement les performances dans certaines occasions, en particulier dans les moteurs de programme extrêmement monotones tels que les logiciels de création vidéo et de traitement de la photo.
Dans le cas où une partie de la CPU superscalaire est et une partie est non, la partie qui ne subit une pénalité de performance due à des stands d'ordonnancement. Le processeur Intel P5 Pentium avait deux ALUs superscalaire qui pourrait accepter une instruction par cycle d'horloge chacun, mais sa FPU ne pouvait pas accepter une instruction par cycle d'horloge. Ainsi, le P5 était entier superscalaire mais pas en virgule flottante superscalaire. Le successeur d'Intel à l'architecture de P5, P6, a ajouté capacités superscalaires à ses assortis de caractéristiques de points, et donc a donné une augmentation significative de la performance de l'instruction à virgule flottante.
À la fois simple et design superscalaire en pipeline augmentent la ILP d'un CPU en permettant à un seul processeur pour terminer l'exécution d'instructions à des taux dépassant une instruction par cycle (IPC). La plupart des modèles de CPU modernes sont au moins quelque peu superscalaire, et presque tous les processeurs à usage général conçus dans la dernière décennie sont superscalaire. Des années plus tard une partie de l'accent dans la conception des ordinateurs haute ILP a été déplacé sur le matériel de la CPU et dans son interface du logiciel, ou ISA. La stratégie du mot d'instruction très long (VLIW) provoque une certaine ILP pour devenir implicitement ou directement par le logiciel, ce qui réduit la quantité de travail de la CPU doit accomplir pour stimuler ILP et réduisant ainsi la complexité de la conception.
parallélisme au niveau de filetage
Une autre stratégie d'atteindre la performance est d'exécuter plusieurs programmes ou threads en parallèle. Ce domaine de recherche est connu comme le calcul parallèle. En La taxonomie de Flynn, cette stratégie est connue sous plusieurs instructions-données multiples ou MIMD.
Une technologie utilisée à cette fin a été multitraitement (MP). La saveur initiale de cette technologie est connue sous le nom de multitraitement symétrique (SMP), où un petit nombre de processeurs partagent une vision cohérente de leur système de mémoire. Dans ce schéma, chaque CPU possède un matériel supplémentaire pour maintenir une vue constamment à jour de la mémoire. En évitant vues rassis de la mémoire, les processeurs peuvent coopérer sur le même programme et les programmes peuvent migrer d'un processeur à l'autre. Pour augmenter le nombre de processeurs de coopération au-delà d'une poignée, des programmes tels que l'accès non uniforme mémoire (NUMA) et protocoles de cohérence basée sur le répertoire ont été introduits dans les années 1990. Systèmes SMP sont limitées à un petit nombre de processeurs tandis que les systèmes NUMA ont été construits avec des milliers de processeurs. Initialement, le multitraitement a été construit en utilisant les processeurs et les conseils discrets multiples pour mettre en œuvre l'interconnexion entre les processeurs. Lorsque les processeurs et leur interconnexion sont toutes mises en œuvre sur une seule puce de silicium, la technologie est connu comme un processeur multi-core.
Il a plus tard été reconnu que plus fine-grain parallélisme existait avec un seul programme. Un seul programme peut avoir plusieurs threads (ou fonctions) qui pourraient être exécutés séparément ou en parallèle. Certains des premiers exemples de cette technologie mise en oeuvre d'entrée / de sortie de traitement tels que l'accès direct à la mémoire comme un thread séparé depuis le thread de calcul. Une approche plus globale de cette technologie a été introduite dans les années 1970 lorsque les systèmes ont été conçus pour exécuter plusieurs threads de calcul en parallèle. Cette technologie est connue comme le multi-threading (MT). Cette approche est considérée comme plus rentable que le multitraitement, que seul un petit nombre de composants au sein d'un CPU est répliquée pour soutenir MT par opposition à l'ensemble de la CPU dans le cas de MP. En MT, les unités d'exécution et le système de mémoire, y compris les caches sont partagés entre plusieurs threads. L'inconvénient de MT est que le support matériel pour le multithreading est plus visible pour le logiciel que celui de député et donc le logiciel de supervision comme les systèmes d'exploitation doivent subir des changements plus importants à l'appui de MT. Un type de MT qui a été mis en œuvre est connu comme bloc multithreading, où un thread est exécuté jusqu'à ce qu'il soit bloqué en attente de données à renvoyer de la mémoire externe. Dans ce schéma, le CPU serait alors passer rapidement à un autre thread qui est prêt à fonctionner, le commutateur fait souvent en un cycle d'horloge du processeur, telles que la technologie UltraSPARC. Un autre type de MT est connu comme simultaneous multithreading, où les instructions de plusieurs threads sont exécutés en parallèle dans un cycle d'horloge du processeur.
Depuis plusieurs décennies, des années 1970 au début des années 2000, l'accent dans la conception de processeurs haute performance à usage général était en grande partie sur la réalisation de haute ILP grâce à des technologies telles que le pipelining, caches, l'exécution superscalaire, out-of-order exécution, etc. Cette tendance a culminé en grande , CPU avides de pouvoir tels que le processeur IntelPentium 4. Au début des années 2000, les concepteurs de CPU ont été contrariés d'atteindre des performances supérieures de techniques ILP en raison de la disparité croissante entre les fréquences de fonctionnement de la CPU et principales fréquences de fonctionnement de la mémoire ainsi que l'escalade de la puissance du processeur dissipation dû aux techniques ILP plus ésotériques.
concepteurs de CPU alors emprunté des idées de marchés informatiques commerciaux tels quele traitement des transactions, où le rendement global des programmes multiples, aussi connu commel'informatique débit, était plus important que la performance d'un seul fil ou d'un programme.
Ce renversement de l'accent est mis en évidence par la prolifération des dual core et multiple CMP (niveau puce multitraitement) conçoit et notamment, les nouveaux modèles d'Intel ressemblant moins superscalaire son architecture P6. Conceptions tardives dans plusieurs familles de processeurs exposition CMP, y compris le x86-64 Opteron et Athlon 64 X2, le SPARC UltraSPARC T1, IBM POWER4 et POWER5, ainsi que plusieurs consoles de jeux vidéo CPU comme le design de PowerPC triple-core de la Xbox 360, et de la 7-core PS3 microprocesseur Cell.
parallélisme de données
Un paradigme moins courant, mais plus en plus important de processeurs (et en effet, l'informatique en général) traite de parallélisme de données. Les processeurs évoquées plus haut sont tous appelés certain type de dispositif scalaire. Comme son nom l'indique, les processeurs vectoriels face à de multiples éléments de données dans le cadre d'une instruction. Cela contraste avec les processeurs scalaires, qui traitent avec un morceau de données pour chaque instruction. Utilisation La taxonomie de Flynn, ces deux régimes de traitement des données sont généralement appelé SIMD (d'instruction unique, données multiples) et SISD (instruction unique, données unique), respectivement. La grande utilité dans la création de processeurs qui traitent avec des vecteurs de données réside dans l'optimisation des tâches qui ont tendance à exiger la même opération (par exemple, une somme ou d'un produit scalaire) à effectuer sur un grand ensemble de données. Certains exemples classiques de ces types de tâches sont les applications multimédia (images, vidéo et son), ainsi que de nombreux types de tâches scientifiques et techniques. Alors qu'un CPU scalaire doit compléter l'ensemble du processus d'extraction, le décodage et l'exécution de chaque instruction et la valeur d'un ensemble de données, un processeur vectoriel peut effectuer une seule opération sur un relativement grand ensemble de données avec une instruction. Bien sûr, cela est possible uniquement lorsque la demande a tendance à exiger beaucoup d'étapes qui appliquent une opération à un grand ensemble de données.
La plupart des processeurs vectoriels début, comme le Cray-1, ont été associés presque exclusivement avec des scientifiques et de recherche cryptographie applications. Cependant, comme le multimédia a largement déplacé vers les médias numériques, la nécessité d'une certaine forme de SIMD dans les CPU usage général est devenue importante. Peu de temps après inclusion de virgule flottante unités d'exécution a commencé à devenir monnaie courante dans les processeurs à usage général, et des spécifications pour les implémentations de SIMD unités d'exécution ont commencé à apparaître pour les processeurs à usage général. Certains de ces spécifications SIMD début comme HP Accélération multimédia extensions (MAX) et d'Intel MMX étaient entier seule. Cette avéré être un obstacle important pour certains développeurs de logiciels, car la plupart des applications qui bénéficient de SIMD traiter principalement des nombres à virgule flottante. Progressivement, ces premiers modèles ont été affinés et refaits dans certaines des spécifications SIMD modernes communes, qui sont habituellement associés à un ISA. Quelques exemples modernes notables sont d'Intel SSE et le PowerPC liés AltiVec (également connu sous le VMX).
Performance
Le rendement ou la vitesse d'un processeur dépend de la fréquence d'horloge (en général donné par multiples de hertz) et les instructions par cycle d'horloge (IPC), qui sont en même temps les facteurs pour les instructions par seconde (IPS) que le processeur peut exécuter. Beaucoup ont déclaré des valeurs IPS ont représenté "pic" taux d'exécution sur des séquences d'instructions artificiels avec quelques branches, tandis que les charges de travail réalistes consistent en un mélange d'instructions et d'applications, dont certains prennent plus de temps à exécuter que d'autres. La performance de la hiérarchie mémoire affecte aussi considérablement les performances du processeur, un problème à peine pris en compte dans les calculs MIPS. En raison de ces problèmes, différents tests standardisés, souvent appelés «repères» pour cette fin-comme SPECint - ont été développés pour tenter de mesurer la véritable performance efficace dans les applications couramment utilisées.
performances de traitement des ordinateurs est augmentée en utilisant des processeurs multi-core, qui est essentiellement de brancher deux ou plusieurs processeurs individuels (appelés noyaux dans ce sens) dans un seul circuit intégré . Idéalement, un processeur dual core serait presque deux fois plus puissant qu'un processeur simple core. En pratique, toutefois, le gain de performance est beaucoup moins, seulement environ 50%, grâce à des algorithmes logiciels imparfaits et mise en œuvre. L'augmentation du nombre de cœurs dans un processeur (c.-à-dual-core, quad-core, etc.) augmente la charge de travail qui peut être manipulé. Cela signifie que le processeur peut maintenant gérer de nombreux événements asynchrones, interruptions, etc., qui peuvent prendre un péage sur le CPU (Central Processing Unit) lorsque submergé. Ces noyaux peuvent être considérés comme des étages différents dans une usine de transformation, avec chaque étage de manutention une tâche différente. Parfois, ces noyaux vont gérer les mêmes tâches que les noyaux adjacents à eux si un noyau unique ne suffit pas de traiter l'information.