

La síntesis de voz
Antecedentes
SOS Children produjo este sitio web para las escuelas, así como este sitio web video sobre África . Haga clic aquí para obtener información sobre el apadrinamiento de niños.

La síntesis de voz es la producción artificial de humanos discurso. Un sistema informático utilizado para este propósito se llama un sintetizador de voz, y puede ser implementado en software o Los productos de hardware. Un texto a voz (TTS) sistema convierte el texto normal del lenguaje en el habla; otros sistemas hacen representaciones lingüísticas simbólicos como transcripciones fonéticas en voz.
Habla sintetizada se puede crear mediante la concatenación de piezas de voz grabada que se almacenan en una base de datos. Los sistemas difieren en el tamaño de las unidades de habla almacenados; un sistema que almacena teléfonos o difonos proporciona el rango de salida más grande, pero pueden carecer de claridad. Para los dominios de uso específicas, el almacenamiento de palabras o frases enteras permite la salida de alta calidad. Alternativamente, un sintetizador puede incorporar un modelo de la tracto vocal y otras características de la voz humana para crear una salida de voz completamente "sintético".
La calidad de un sintetizador de voz se juzga por su similitud con la voz humana y por su capacidad para ser entendido. Un programa inteligible de texto a voz permite a las personas con impedimentos visuales o leer discapacidad para escuchar a las obras escritas en un ordenador personal. Muchos sistemas operativos han incluido los sintetizadores de voz desde principios de 1990.
 | Anuncio automática Una voz sintética anunciando un tren que llegan a Suecia . |
| ¿Problemas al reproducir este archivo? Ver ayuda de medios. | |
| Muestra de Microsoft Sam Microsoft Windows XP 's discurso predeterminado sintetizador de voz que dice " Pangrama 1234567890 veces. así que " |
| ¿Problemas al reproducir este archivo? Ver ayuda de medios. | |
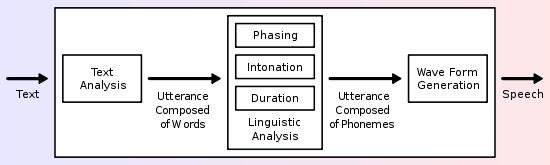
Un sistema de conversión de texto a voz (o "motor") se compone de dos partes: una front-end y un back-end. El front-end tiene dos tareas principales. En primer lugar, convierte el texto en bruto que contiene símbolos como números y abreviaturas en el equivalente de palabras escritas-out. Este proceso a menudo se llama normalización de texto, pre-procesamiento, o tokenización. El front-end entonces asigna transcripciones fonéticas a cada palabra, y divide y marca el texto en unidades prosódicos, como frases, cláusulas y frases. El proceso de asignar transcripciones fonéticas a las palabras se llama texto a fonema o conversión grafema-fonema a. Transcripciones fonéticas e información prosodia juntos conforman la representación lingüística simbólica que se emite por el front-end. La parte trasera de extremo a menudo referido como el sintetizador -entonces convierte la representación lingüística simbólica en sonido. En ciertos sistemas, esta parte incluye el cálculo de la prosodia de destino (contorno de tono, las duraciones de fonema), que se impone a continuación, en la voz de salida.
Historia
Mucho antes de electrónica procesamiento de la señal se inventó, hubo quienes trataron de construir máquinas para crear el habla humana. Algunas leyendas tempranas de la existencia de "cabezas que hablan" involucradas Gerberto de Aurillac (d. 1003 dC), Alberto Magno (1198-1280), y Roger Bacon (1214-1294).
En 1779, el danés científico cristiano Kratzenstein, trabajando en el Academia de Ciencias de Rusia, los modelos construidos de lo humano tracto vocal que podrían producir los cinco largos de vocales sonidos (en Internacional notación alfabeto fonético, son [A], [e], [i], [o] y [u]). Esto fue seguido por la operado-fuelle " máquina acústica de voz-mecánico "por Wolfgang von Kempelen de Presburgo , Hungría , describe en un artículo 1791. Esta máquina añadió modelos de la lengua y los labios, que le permite producir consonantes , así como las vocales. En 1837, Charles Wheatstone produjo una "máquina parlante", basada en el diseño de von Kempelen, y en 1857, M. Faber construyó el "Jilguero". Diseño de Wheatstone fue resucitado en 1923 por Paget.
En la década de 1930, Laboratorios Bell desarrolló el vocoder, que analiza automáticamente la voz en su tono y resonancias fundamental. A partir de su trabajo en el vocoder, Homer Dudley desarrollado un sintetizador de voz manualmente teclado que funcionan con llama El Voder (Demostrador de voz), que expuso en la 1939 Feria Mundial de Nueva York.
La Reproducción del patrón fue construido por Dr. Franklin S. Cooper y sus colegas Haskins Laboratories en la década de 1940 y se terminó en 1950. Hubo varias versiones diferentes de este dispositivo de hardware, pero sólo uno sobrevive actualmente. La máquina convierte imágenes de los patrones acústicos del habla en forma de un espectrograma de nuevo en sonido. El uso de este dispositivo, Alvin Liberman y sus colegas fueron capaces de descubrir las señales acústicas para la percepción de segmentos fonéticos (consonantes y vocales).
Sistemas dominantes en los años 1980 y 1990 fueron el sistema MiTalk, basado en gran medida en el trabajo de Dennis Klatt en el MIT, y el sistema de Bell Labs; este último fue uno de los primeros sistemas independientes del lenguaje multilingües, haciendo uso extensivo de métodos de procesamiento de lenguaje natural.
Sintetizadores de voz electrónicos tempranos sonaban robótica y eran a menudo apenas inteligible. La calidad de la voz sintetizada ha mejorado constantemente, pero la producción de sistemas de síntesis de voz contemporánea sigue siendo claramente distinguible de la voz humana real.
Como la relación costo-rendimiento hace que los sintetizadores de voz cada vez más barato y más accesible a la gente, más personas se beneficiarán de la utilización de programas de conversión de texto a voz.
Dispositivos electrónicos
Los primeros sistemas de síntesis de voz basados en computadoras fueron creadas a finales de 1950. El primer sistema general Inglés-texto-a-voz fue desarrollado por Noriko Umeda et al., En 1968 en el Laboratorio de Electrotécnica, Japón. En 1961, el físico John Larry Kelly, Jr. y su colega Louis Gerstman utilizaron un IBM 704 equipo para sintetizar el habla, un evento entre los más destacados en la historia de Bell Labs. Sintetizador de la grabadora de voz de Kelly ( vocoder) recrea la canción " Daisy Bell ", con el acompañamiento musical de Max Mathews. Coincidentemente, Arthur C. Clarke estaba visitando a su amigo y colega John Pierce en las instalaciones de los Laboratorios Bell de Murray Hill. Clarke quedó tan impresionado por la demostración de que él lo utilizó en la escena culminante de su guión para su novela 2001: Una odisea del espacio, donde el HAL 9000 computadora canta la misma canción a medida que se pone a dormir por el astronauta De Dave Bowman. A pesar del éxito de la síntesis de voz puramente electrónico, la investigación todavía está siendo llevado a cabo en los sintetizadores de voz mecánicos.
Electrónicos de mano que ofrece la síntesis de voz han empezado a surgir en la década de 1970. Uno de los primeros fue el Telesensory Systems Inc. (ETI) del Habla + calculadora portátil para ciegos en 1976. Otros dispositivos se produjeron principalmente con fines educativos, como Speak & Spell, producido por Texas Instruments en 1978. Fidelity lanzado una versión habla de su computadora de ajedrez electrónico en 1979. El primer videojuego para presentar la síntesis de voz era el 1980 dispara a todos juego arcade, Stratovox, desde Sun Electronics. Otro de los primeros ejemplos fue la versión arcade de Berzerk, lanzado ese mismo año. La primera multi-jugador juego electrónico síntesis utilizando voz era Milton de Milton Bradley Company, que produjo el dispositivo en 1980.
Tecnologías Sintetizador
Las cualidades más importantes de un sistema de síntesis de voz son la naturalidad y la inteligibilidad. Naturalidad describe cómo estrechamente suena la salida como el habla humana, mientras que la inteligibilidad es la facilidad con la que se entiende la salida. El sintetizador de habla ideal es natural y comprensible. Sistemas de síntesis de voz por lo general tratan de maximizar ambas características.
Las dos tecnologías principales para la generación de formas de onda del habla sintéticos son la síntesis por concatenación y síntesis de formantes. Cada tecnología tiene sus fortalezas y debilidades, y los usos previstos de un sistema de síntesis se suele determinar qué método se utiliza.
Síntesis por concatenación
La síntesis por concatenación se basa en la concatenación (o encadenar) de segmentos de voz grabada. En general, la síntesis por concatenación produce la voz sintetizada más de sonido natural. Sin embargo, las diferencias entre las variaciones naturales en el habla y la naturaleza de las técnicas automatizadas para la segmentación de las formas de onda a veces dan lugar a problemas técnicos audibles en la salida. Hay tres principales subtipos de síntesis por concatenación.
Síntesis de selección de unidad
Síntesis de selección de unidad utiliza grandes bases de datos de voz grabada. Durante la creación de la base de datos, cada enunciado grabado se segmenta en algunos o todos de los siguientes: individuo móviles, difonos, medias móviles, sílabas, morfemas, palabras, frases, y frases. Típicamente, la división en segmentos se realiza mediante una especialmente modificado reconocedor de voz en un modo de "alineación forzada" con un poco de corrección manual después, usando representaciones visuales tales como la forma de onda y espectrograma. Una índice de las unidades en la base de datos de voz es entonces creado en base a los parámetros de segmentación y acústicas como el frecuencia fundamental ( pitch), duración, posición en la sílaba, y vecinos móviles. En tiempo de ejecución, la expresión diana deseada se crea mediante la determinación de la mejor cadena de unidades de candidatos a partir de la base de datos (selección de la unidad). Este proceso se logra típicamente usando un especialmente ponderada árbol de decisión.
Selección de unidad proporciona la mayor naturalidad, porque sólo se aplica una pequeña cantidad de procesamiento de señal digital (DSP) para la voz grabada. DSP a menudo hace que el habla grabada sonido menos natural, aunque algunos sistemas utilizan una pequeña cantidad de procesamiento de la señal en el punto de concatenación para suavizar la forma de onda. La salida de los mejores sistemas de selección de unidad es a menudo indistinguible de voces humanas reales, especialmente en contextos para los cuales el sistema TTS ha sido afinados. Sin embargo, la máxima naturalidad requieren típicamente bases de datos de voz de selección de unidad a ser muy grande, en algunos sistemas que van en el gigabytes de datos registrados, que representan a decenas de horas de discurso. Además, los algoritmos de selección de unidad se han conocido para seleccionar segmentos de un lugar que se traduce en menos de síntesis ideal (por ejemplo, las palabras se convierten en menores claro), incluso cuando existe una mejor opción en la base de datos. Recientemente, los investigadores han propuesto varios métodos automatizados para detectar segmentos no naturales en los sistemas de síntesis de voz de selección de unidad.
Síntesis difonos
Síntesis difonos utiliza una base de datos de voz mínimo que contiene toda la difonos (transiciones y del sonido a sonido) que se producen en un idioma. El número de difonos depende de la fonotáctica de la lengua: por ejemplo, el español tiene unos 800 difonos y alemán sobre 2500. En síntesis difonos, sólo un ejemplo de cada uno de difonos figura en la base de datos de voz. En tiempo de ejecución, el objetivo prosodia de una oración se superpone a estas unidades mínimas mediante técnicas de procesamiento de señales digitales, como codificación predictiva lineal, PSOLA o MBRLOLA. La síntesis de difonos adolece de los problemas técnicos sónicas de la síntesis por concatenación y la naturaleza-robótico de resonancia de síntesis de formantes, y tiene algunas de las ventajas de cualquiera de los enfoques distintos de pequeño tamaño. Como tal, su uso en aplicaciones comerciales está disminuyendo, aunque sigue siendo utilizado en la investigación debido a que hay un número de implementaciones de software libremente disponibles.
Síntesis de dominio específico
Palabras y frases específicas de dominio concatena síntesis pregrabado para crear expresiones completas. Se utiliza en aplicaciones en las que la variedad de textos la salida de voluntad sistema está limitado a un dominio particular, como anuncios sobre el programa de tránsito o información meteorológica. La tecnología es muy fácil de implementar, y ha estado en uso comercial desde hace mucho tiempo, en dispositivos como hablar relojes y calculadoras. El nivel de naturalidad de estos sistemas puede ser muy alto debido a la variedad de tipos de oraciones es limitado, y que coincide estrechamente la prosodia y entonación de las grabaciones originales.
Debido a que estos sistemas están limitados por las palabras y frases en sus bases de datos, no son de uso general y sólo pueden sintetizar las combinaciones de palabras y frases con los que han sido preprogramados. La combinación de palabras dentro de lenguaje hablado naturalmente sin embargo todavía puede causar problemas si no se toman en cuenta las muchas variaciones. Por ejemplo, en dialectos no rhotic de Inglés de la "r" en palabras como "clara" / klɪə / es por lo general sólo se pronuncia cuando la siguiente palabra tiene una vocal como su primera carta (por ejemplo, "limpiar" se realiza como / ˌklɪəɾʌʊt /). Asimismo, en francés , muchas consonantes finales se convierten en no más silencioso si es seguido por una palabra que comienza con una vocal, un efecto llamado enlace. Este alternancia no puede ser reproducido por un sistema de palabra-concatenación simple, que requiere una complejidad adicional para ser contextual.
Síntesis de formantes
Síntesis de formantes no usa muestras de voz humana en tiempo de ejecución. En lugar de ello, la salida de voz sintetizada se ha creado usando síntesis aditiva y un modelo acústico ( síntesis de modelado físico). Parámetros como frecuencia fundamental, sonoridad, y los niveles de ruido se cambian con el tiempo para crear un forma de onda de voz artificial. Este método se llama a veces basado en normas de síntesis; Sin embargo, muchos sistemas concatenativa también tienen componentes basados en reglas. Muchos de los sistemas basados en la tecnología de síntesis de formantes generan artificial discurso, robótica sonar que nunca se puede confundir con el habla humana. Sin embargo, la máxima naturalidad no es siempre el objetivo de un sistema de síntesis de voz, y sistemas de síntesis de formantes tienen ventajas sobre los sistemas de concatenación. Discurso Formant-sintetizado puede ser fiable inteligible, incluso a velocidades muy altas, evitando los problemas técnicos acústicos que comúnmente afectan a los sistemas de concatenación. Voz sintetizada de alta velocidad es utilizado por personas con discapacidad visual para navegar rápidamente equipos mediante una lector de pantalla. Sintetizadores de formantes son programas generalmente más pequeños que los sistemas de concatenación, ya que no tienen una base de datos de muestras de voz. Por tanto, pueden ser utilizados en sistemas integrados, donde memoria y alimentación del microprocesador son especialmente limitados. Debido a que los sistemas basados en formantes tienen un control completo de todos los aspectos de la voz de salida, una amplia variedad de prosodias y entonaciones se pueden emitir, transmitir no sólo preguntas y declaraciones, sino una variedad de emociones y tonos de voz.
Ejemplos de tiempo no real, pero el control de una entonación muy precisa en la síntesis de formantes incluyen el trabajo realizado a finales de 1970 para la Juguete Texas Instruments Speak & Spell, y en la década de 1980 Sega máquinas recreativas y en muchos Juegos de arcade de Atari, Inc. utilizando el TMS5220 LPC Chips. Creación de la entonación adecuada para estos proyectos fue laborioso, y los resultados aún no han sido igualados por tiempo real de interfaces de conversión de texto a voz.
Síntesis articulatoria
Síntesis articulatoria refiere a las técnicas computacionales para sintetizar discurso basado en modelos de la humana tracto vocal y los procesos de articulación que se producen allí. El primer sintetizador articulatorio utilizado regularmente para experimentos de laboratorio se desarrolló en Haskins Laboratories en la década de 1970 por Philip Rubin, Tom Baer y Paul Mermelstein. Este sintetizador, conocido como ASY, se basó en modelos del tracto vocal desarrolladas en Laboratorios Bell en los años 1960 y 1970 por Paul Mermelstein, Cecil Coker, y sus colegas.
Hasta hace poco, los modelos de síntesis articulatoria no se han incorporado en los sistemas de síntesis de voz comerciales. Una excepción notable es la Sistema basado en NeXT originalmente desarrollado y comercializado por Trillium Investigación de sonido, una empresa spin-off de la Universidad de Calgary, donde gran parte de la investigación original, se llevó a cabo. Tras la desaparición de las diversas encarnaciones de NeXT (iniciado por Steve Jobs a finales de 1980 y se fusionó con Apple Computer en 1997), el software Trillium se publicó bajo el Licencia Pública General de GNU, con el trabajo continuo como gnuspeech. El sistema, comercializados por primera vez en 1994, ofrece la conversión total a base de articulatorio de texto a voz utilizando una guía de onda o de línea de transmisión analógica de las vías nasales y orales humanos controlados por el "modelo de la región distintiva" de Carré.
Síntesis basada HMM-
Síntesis basado en HMM es un método de síntesis basado en modelos ocultos de Markov, también llamados Statistical Parametric Síntesis. En este sistema, el espectro de frecuencia ( tracto vocal), frecuencia fundamental (fuente vocal), y la duración ( prosodia) de expresión se modelan simultáneamente por HMMs. Discurso formas de onda se generan a partir de HMMs sí mismos basado en el criterio de máxima verosimilitud.
Síntesis de onda sinusoidal
Síntesis de onda sinusoidal es una técnica para sintetizar el habla mediante la sustitución de la formantes (principales bandas de energía) con silbidos de tonos puros.
Desafíos
Retos de normalización texto
El proceso de normalización de texto rara vez es sencillo. Textos están llenos de heterónimos, números , y abreviaturas que todos requieren la expansión en una representación fonética. Hay muchas grafías en Inglés que se pronuncian de forma distinta según el contexto. Por ejemplo, "Mi último proyecto es aprender cómo proyectar mejor mi voz" contiene dos pronunciaciones de "proyecto".
La mayoría de texto a voz sistemas (TTS) no generan representaciones semánticas de sus textos de entrada, como los procesos para hacerlo no son fiables, bien entendida, o computacionalmente eficaz. Como resultado, diversos técnicas heurísticas se utilizan para adivinar la forma correcta de eliminar la ambigüedad homógrafos, al igual que el examen de las palabras vecinas y el uso de estadísticas sobre la frecuencia de ocurrencia.
Recientemente sistemas TTS han comenzado a utilizar los HMM (discutido anteriormente) para generar "partes de la oración" para ayudar en la desambiguación de homógrafos. Esta técnica es bastante éxito durante muchos casos como si "leer" debe ser pronunciado como "rojo", implicando tiempo pasado, o como "caña", implicando tiempo presente. Las tasas de error típicos cuando se utiliza HMMs de esta manera son generalmente debajo de cinco por ciento. Estas técnicas también funcionan bien para la mayoría de las lenguas europeas, aunque el acceso a la formación necesaria corpus es frecuentemente difícil en estos idiomas.
Decidir cómo convertir números es otro problema que TTS sistemas tienen que abordar. Es un desafío de programación sencillo para convertir un número en palabras (al menos en Inglés), como "1325", convirtiéndose en "un mil trescientos veinticinco." Sin embargo, los números se producen en muchos contextos diferentes; "1325" también puede leerse como "uno tres dos cinco", "1325" o "mil trescientos veinticinco". Un sistema TTS a menudo puede inferir cómo expandir un número basado en palabras del contexto, números y puntuacion, y en ocasiones el sistema proporciona una forma de especificar el contexto si es ambiguo. Números romanos también se pueden leer de manera diferente dependiendo del contexto. Por ejemplo, "Enrique VIII", se lee como "Enrique VIII", mientras que "el Capítulo VIII" se lee como "Capítulo Ocho".
Del mismo modo, las abreviaturas pueden ser ambiguos. Por ejemplo, la abreviatura "en" para "pulgadas" debe diferenciarse de la palabra "en", y la dirección "12 St John St." utiliza la misma abreviatura para tanto "Santo" y "la calle". Sistemas TTS con extremos delanteros inteligentes pueden hacer conjeturas acerca de abreviaturas ambiguas educado, mientras que otros proporcionan el mismo resultado en todos los casos, lo que resulta en salidas sin sentido (y, a veces cómicos), como "cooperación" que se queden como "operación de la empresa".
Desafíos de texto a fonema
Sistemas de síntesis de voz utilizan dos enfoques básicos para determinar la pronunciación de una palabra en función de su ortografía, un proceso que a menudo se llama texto a fonema o-grafema-fonema a la conversión ( fonema es el término utilizado por los lingüistas para describir sonidos distintivos en un idioma). El método más sencillo para la conversión de texto a fonema es el enfoque basado en el diccionario, donde un gran diccionario que contiene todas las palabras de una lengua y sus pronunciaciones correctas es almacenada por el programa. La determinación de la pronunciación correcta de cada palabra es una cuestión de buscar cada palabra en el diccionario y la sustitución de la ortografía con la pronunciación especificada en el diccionario. El otro enfoque, basado en normas, en el que se aplican las normas de pronunciación de palabras para determinar sus pronunciaciones basado en su ortografía. Esto es similar a la "sondear", o fonética sintética, enfoque de aprendizaje de la lectura.
Cada método tiene ventajas y desventajas. El enfoque basado en el diccionario es rápida y precisa, pero falla completamente si se le da una palabra que no está en su diccionario. Como el tamaño del diccionario crece, también lo hace los requisitos de espacio de memoria del sistema de síntesis. Por otro lado, el enfoque basado en la regla funciona en cualquier entrada, pero la complejidad de las normas crece sustancialmente como el sistema toma en cuenta la ortografía o pronunciaciones irregulares. (Tenga en cuenta que la palabra "de" es muy común en Inglés, sin embargo, es la única palabra en la que la letra "f" se pronuncia [v].) Como resultado, casi todos los sistemas de síntesis de voz utilizan una combinación de estos enfoques.
Los idiomas con un Ortografía fonética tiene un sistema muy regular por escrito, y la predicción de la pronunciación de palabras basado en su ortografía es bastante exitoso. Sistemas de síntesis de voz para estas lenguas a menudo usan el método basado en normas ampliamente, recurrir a diccionarios sólo para esas pocas palabras, como nombres y préstamos del exterior, cuya pronunciación no son evidentes a partir de su ortografía. Por otro lado, los sistemas de síntesis de voz para idiomas como el Inglés , que tienen sistemas de escritura extremadamente irregulares, son más propensos a confiar en los diccionarios, y el uso de métodos basados en reglas sólo para palabras inusuales, o palabras que no están en sus diccionarios.
Desafíos de evaluación
La evaluación constante de los sistemas de síntesis de voz puede resultar difícil debido a la falta de criterios objetivos de evaluación acordados universalmente. Diferentes organizaciones a menudo utilizan diferentes datos de voz. La calidad de los sistemas de síntesis del habla también depende en gran medida de la calidad de la técnica de producción (que puede implicar analógica o grabación digital) y en las instalaciones utilizadas para reproducir el discurso. La evaluación de los sistemas de síntesis de voz ha sido, por tanto, a menudo comprometida por diferencias entre las técnicas de producción y las instalaciones de repetición.
Recientemente, sin embargo, algunos investigadores han comenzado a evaluar los sistemas de síntesis de voz utilizando un conjunto de datos del habla común.
Prosodics y contenido emocional
Un estudio en la revista Comunicación Discurso de Amy Drahota y sus colegas de la Universidad de Portsmouth, Reino Unido , informó que los oyentes puedan expresar grabaciones podrían determinar, al mejor de los niveles de azar, sea o no el altavoz estaba sonriendo. Se sugirió que la identificación de las características vocales que indican el contenido emocional puede ser utilizado para ayudar a que el sonido de voz sintetizada más natural.
Hardware dedicado
Precoz de Tecnologías (No disponible)
- Votrax
- SC-01A (formante analógica) http://en.wikipedia.org/wiki/File:TextSpeak_Embedded_Text_to_Speech_on_a_Chip.jpg
- SC-02 / SSI-263 / "Artic 263"
- Instrumentación general SP0256-AL2 (CTS256A-AL2)
- National Semiconductor DT1050 Digitalker (Mozer - Forrest Mozer)
- Sistemas de silicio SSI 263 (formante analógica)
- Texas Instruments LPC Discurso chips ** ** TMS5110A TMS5200
- MSP50C6XX - Vendido a Sensorial, Inc. en 2001
Actual (a partir de 2013)
- Magnevation SpeakJet (www.speechchips.com) TTS256 Hobby y experimentador.
- Epson S1V30120F01A100 (www.epson.com) voz Basado IC DECTalk, Robótica, Ing / Español
- Textspeak TTS-EM (www.textspeak.com) ICs, Módulos y recintos industriales en 24 idiomas. Sonido humano, basado fonemas.
Sistemas operativos de ordenador o puntos de venta con la síntesis de voz
Atari
Podría decirse que el primer sistema de voz integrado en una sistema operativo fue el 1400XL / 1450XL ordenadores personales diseñado por Atari, Inc. utilizando el chip Votrax SC01 en 1983. Los ordenadores El 1400XL / 1450XL utilizado una máquina de estados finitos para permitir Ortografía Inglés mundial en la síntesis de texto a voz. Por desgracia, el 1400XL / ordenadores personales 1450XL nunca enviado en cantidad.
La Ordenadores Atari ST fueron vendidos con "stspeech.tos" en disquete.
Manzana
El primer sistema de voz integrado en una sistema operativo que se suministra en cantidad fue Apple Computer 's MacinTalk en 1984. El software fue licenciado de los desarrolladores de 3 ª parte Joseph Katz y Mark Barton (más tarde, SoftVoice, Inc.) y se presentó durante el 1984 la introducción de la computadora Macintosh. Desde la década de 1980 ordenadores Macintosh ofrecen el texto a las capacidades de voz a través del software MacinTalk. A principios de 1990 de Apple amplió su amplio apoyo de conversión de texto a voz capacidades sistema ofrenda. Con la introducción de los ordenadores basados en PowerPC más rápidos que incluyen el muestreo de voz de mayor calidad. Apple también presentó el reconocimiento de voz en sus sistemas que proporcionan un conjunto de comandos de fluido. Más recientemente, Apple ha añadido voces basadas en muestras. Comenzando como una curiosidad, el sistema de voz de Apple, Macintosh ha evolucionado hasta convertirse en un programa totalmente compatible, PlainTalk, para las personas con problemas de visión. VoiceOver era la primera vez que aparece en Mac OS X Tiger (10.4). Durante 10.4 (Tiger) y primeros lanzamientos de 10.5 (Leopard) sólo había una voz estándar envío con Mac OS X. A partir de 10.6 (Snow Leopard), el usuario puede elegir de una amplia lista de gama de múltiples voces. Voces de VoiceOver cuentan la toma de respiraciones con un sonido realista entre oraciones, así como una mejor claridad a altas velocidades de lectura más PlainTalk. Mac OS X también incluye por ejemplo, una aplicación basada en la línea de comandos que convierte texto en voz audible. La AppleScript Standard Adiciones incluye una decir verbo que permite una secuencia de comandos para utilizar cualquiera de las voces instaladas y controlar el tono, velocidad de la voz y la modulación del texto hablado.
La Manzana sistema operativo iOS usado en el iPhone, iPad y iPod Touch utiliza Síntesis de voz VoiceOver para la accesibilidad. Algunas aplicaciones de terceros también ofrecen la síntesis de voz para facilitar la navegación, la lectura de páginas web o traducir texto.
AmigaOS
El segundo sistema operativo con la capacidad de síntesis de voz avanzado que era AmigaOS, introducido en 1985. La síntesis de voz fue licenciado por Commodore Internacional de SoftVoice, Inc., quien también desarrolló el MacinTalk originales sistema de conversión de texto a voz. Contaba con un completo sistema de emulación de voz, tanto con voces masculinas y femeninas y de "estrés" marcadores indicador, hecho posible por las características avanzadas del Amiga de audio hardware chipset. Se divide en un dispositivo de narrador y una biblioteca traductor. Amiga Habla Handler contó con un traductor de texto a voz. AmigaOS considera síntesis de voz de un dispositivo de hardware virtual, por lo que el usuario podría incluso redirigir la salida de la consola a la misma. Algunos programas de Amiga, como procesadores de texto, hizo un amplio uso del sistema de voz.
Microsoft Windows
Modernos de Windows sistemas de escritorio pueden usar SAPI 4 y SAPI 5 componentes para apoyar la síntesis de voz y reconocimiento de voz. SAPI 4.0 estaba disponible como opcional add-on para Windows 95 y Windows 98. Windows 2000 añadió Narrador, una utilidad de conversión de texto a voz para las personas que tienen discapacidad visual. Los programas de terceros como CoolSpeech, Textaloud y Ultra Hal puede realizar varias tareas de conversión de texto a voz, como la lectura de textos en voz alta de un sitio web determinado, cuenta de correo electrónico, documentos de texto, el portapapeles de Windows, pulsa el teclado del usuario, etc. No todos los programas pueden utilizar la síntesis de voz directamente. Algunos programas pueden utilizar los plug-ins, extensiones o complementos para leer el texto en voz alta. Los programas de terceros están disponibles que pueden leer texto desde el portapapeles del sistema.
Microsoft Speech Server es un paquete basado en servidor para la síntesis de voz y el reconocimiento. Está diseñado para su uso con la red aplicaciones web y centros de llamadas.
Text-to-Speech (TTS) se refiere a la capacidad de los ordenadores para leer el texto en voz alta. Un motor TTS convierte el texto escrito a una representación fonológica, luego convierte la representación fonológica de las formas de onda que pueden salir como sonido. Motores TTS con diferentes idiomas, dialectos y vocabularios especializados están disponibles a través de los editores de terceros.
Androide
La versión 1.6 de Android ha añadido soporte para la síntesis de voz (TTS).
Internet
Actualmente, hay un número de aplicaciones, plugins y aparatos que pueden leer los mensajes directamente desde un correo electrónico del cliente y páginas web desde un navegador web o Barra de herramientas de Google como Texto a voz que es un add-on para Firefox . Algunos especializada software puede narrar RSS feeds. Por un lado, RSS-narradores en línea simplifican la entrega de información, permitiendo a los usuarios escuchar sus fuentes de noticias favoritas y convertirlos a podcasts . Por otra parte, en línea RSS-readers están disponibles en casi cualquier PC conectado a Internet. Los usuarios pueden descargar generado archivos de audio a dispositivos portátiles, por ejemplo, con una ayuda de podcast de receptor, y escuchar a ellos al caminar, correr o ir al trabajo.
Un campo creciente de Internet basado TTS es basado en la web tecnología de asistencia, por ejemplo ' La Búsqueda 'de una compañía del Reino Unido y Readspeaker. Puede ofrecer funcionalidad TTS a nadie (por razones de accesibilidad, comodidad, entretenimiento o información) con acceso a un navegador web. El no lucrativa proyecto Pediaphon fue creado en 2006 para proporcionar una interfaz TTS basado en la web similar a la Wikipedia .
Otro trabajo que se está haciendo en el contexto de la W3C a través de la W3C Audio Grupo Incubadora con la participación de la BBC y Google Inc.
Otros
- Algunos lectores de libros electrónicos, como el Amazon Kindle, Samsung E6, PocketBook eReader Pro, eDGe enTourage, y el Bebook Neo.
- Algunos modelos de Texas Instruments ordenadores domésticos producidos en 1979 y 1981 ( Texas Instruments TI-99/4 y TI-99 / 4A) fueron capaces de síntesis o recitar palabras y frases completas (text-to-diccionario de texto a fonema), utilizando un sintetizador de voz muy popular periférico. TI utiliza una propiedad codec para incrustar frases habladas completas en aplicaciones, principalmente los juegos de video.
- IBM 's OS / 2 Warp 4 incluido VoiceType, un precursor IBM ViaVoice.
- Los sistemas que operan en los sistemas de software de código libre y abierto, incluyendo Linux son diversas, e incluyen de código abierto de programas como el Festival de Sistema de síntesis de voz que utiliza la síntesis basada en difonos (y puede utilizar un número limitado de Voces Mbrola), y gnuspeech que utiliza síntesis articulatoria de la Free Software Foundation.
- Las empresas que desarrollan sistemas de síntesis del habla, pero que ya no están en este negocio son incluir Discurso BEST (comprada por L & H), Tecnología Elocuente (comprado por SpeechWorks), Lernout & Hauspie (comprado por Nuance), SpeechWorks (comprado por Nuance), Sistemas retóricas (comprados por Nuance).
- Unidades de navegación GPS producido por Garmin, Magallanes, TomTom y otros utilizan la síntesis de voz para la navegación del automóvil.
Síntesis de voz lenguajes de marcas
Un número de lenguajes de marcas se han establecido para la entrega de texto como de voz en un Compatible con XML formato. La más reciente es Síntesis de voz Markup Language (SSML), que se convirtió en un Recomendación del W3C en 2004. Los lenguajes de marcado de síntesis de voz mayores incluyen Java discurso (lenguaje de marcado JSML) y SABLE. Aunque cada una de ellas se propuso como un estándar, ninguno de ellos ha sido ampliamente adoptado.
Lenguajes de marcado de síntesis de voz se distinguen de los lenguajes de marcado diálogo. VoiceXML, por ejemplo, incluye etiquetas relacionadas con el reconocimiento de voz, gestión del diálogo y la marcación por tonos, además de texto a voz de marcado.
Aplicaciones
La síntesis de voz ha sido durante mucho tiempo un importante herramienta de tecnología de asistencia y su aplicación en este ámbito es significativo y generalizado. Permite barreras ambientales a ser retirados de las personas con una amplia gama de discapacidades. La aplicación más larga ha estado en el uso de lectores de pantalla para personas con sistemas visuales deterioro, pero en texto a voz son ahora comúnmente utilizados por las personas con dislexia y otras dificultades de lectura, así como por los niños pre-alfabetizados. También se emplean con frecuencia para ayudar a aquellos con severa impedimento del habla generalmente a través de un dedicado salida de voz ayuda a la comunicación.
Técnicas de síntesis de voz también se utilizan en producciones de entretenimiento, como juegos y animaciones. En 2007, ANIMO Limited anunció el desarrollo de un paquete de aplicación de software basada en su FineSpeech software de síntesis de voz, orientado explícitamente hacia los clientes en las industrias de entretenimiento, capaz de generar narración y líneas de diálogo de acuerdo a las especificaciones del usuario. La solicitud llegue a la madurez en 2008, cuando NEC Biglobe anunció un servicio web que permite a los usuarios crear frases de las voces de Code Geass: Lelouch de los personajes Rebelión R2.
En los últimos años, a palabras de la discapacidad y las ayudas de comunicación se han convertido en discapacitados ampliamente desplegado en Mass Transit. Texto a voz también está encontrando nuevas aplicaciones fuera del mercado de la discapacidad. Por ejemplo, la síntesis de voz, en combinación con el reconocimiento de voz, permite la interacción con los dispositivos móviles a través de las interfaces de procesamiento de lenguaje natural.