

Determinante
Sabías ...
La organización de una selección de Wikipedia para escuelas en el mundo en desarrollo sin internet fue una iniciativa de SOS Children. patrocinio SOS Niño está genial!
En álgebra , un factor determinante es una función dependiente de n que asocia un escalar, det (A), para cada n × n matriz cuadrada A. El significado geométrico fundamental de un determinante es como la factor de escala para el volumen cuando A es considerado como una transformación lineal. Determinantes son importantes tanto en el cálculo , donde entran en el regla de sustitución de varias variables, y en álgebra multilineal.
Para un número entero positivo n fijo, hay una función determinante único para el n × n matrices sobre cualquier anillo conmutativo R. En particular, existe esta función cuando R es el campo de reales o números complejos .
Notación barra vertical
El determinante de una matriz A veces también se denota por | A |. Esta notación puede ser ambigua, ya que también se utiliza para ciertas normas de la matriz y para el valor absoluto . Sin embargo, a menudo la norma matriz se denota con barras verticales dobles (por ejemplo, ‖ ‖ A) y puede llevar a un subíndice también. Por lo tanto, la notación barra vertical para determinante se utiliza con frecuencia (por ejemplo, La regla de Cramer y menores de edad). Por ejemplo, para la matriz
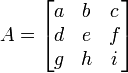
el determinante  podría ser indicado por
podría ser indicado por 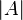 o más explícitamente como
o más explícitamente como
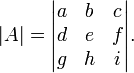
Es decir, los corchetes alrededor de las matrices se sustituyen con barras verticales alargadas.
Determinantes de matrices 2-por-2

La matriz 2 × 2
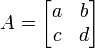
tiene determinante
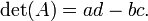
La interpretación cuando la matriz tiene entradas de números reales es que esto da el área orientada de la paralelogramo con vértices en (0,0), (a, b), (a + c, b + d), y (c, d). La zona orientada es el mismo que el habitual zona , excepto que es negativa cuando los vértices se enumeran en orden las agujas del reloj.
El supuesto aquí es que la transformación lineal se aplica a la fila vectores como el producto vectorial de matriz  , Donde
, Donde  es un vector columna. El paralelogramo en la figura se obtiene multiplicando los vectores fila
es un vector columna. El paralelogramo en la figura se obtiene multiplicando los vectores fila  y
y 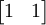 , La definición de los vértices del cuadrado de la unidad. Con el producto matriz-vector más común
, La definición de los vértices del cuadrado de la unidad. Con el producto matriz-vector más común 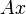 el paralelogramo tiene vértices en
el paralelogramo tiene vértices en 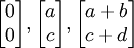 y
y  (Tenga en cuenta que
(Tenga en cuenta que 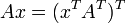 ).
).
Se dará a continuación una fórmula para matrices más grandes.
Determinantes de matrices 3-por-3

La matriz 3 × 3:
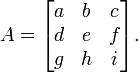
Usando el expansión cofactor en la primera fila de la matriz se obtiene:
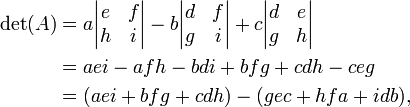

que puede ser recordado como la suma de los productos de tres diagonal noroeste de líneas al sur-este de elementos de la matriz, menos la suma de los productos de tres diagonal suroeste de líneas al noreste de elementos cuando las copias de la primera dos columnas de la matriz se escriben junto a él como a continuación:

Tenga en cuenta que esta regla mnemotécnica no se traslada en dimensiones superiores.
Aplicaciones
Determinantes se utilizan para caracterizar matrices invertibles (es decir, exactamente esas matrices con determinantes distintos de cero), y para describir explícitamente la solución de un sistema de ecuaciones lineales con La regla de Cramer. Se pueden utilizar para encontrar los valores propios de la matriz  a través de polinomio característico
a través de polinomio característico
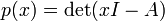
donde I es la matriz de identidad de la misma dimensión que A.
Se piensa a menudo del determinante como la asignación de un número a cada secuencia de  vectores en
vectores en 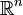 , Mediante el uso de la matriz cuadrada cuyas columnas son los vectores dados. Con este entendimiento, el signo del determinante de una base se puede utilizar para definir la noción de orientación en espacios euclídeos . El determinante de un conjunto de vectores es positivo si forman los vectores de un diestro sistema de coordenadas, y negativo si zurdo.
, Mediante el uso de la matriz cuadrada cuyas columnas son los vectores dados. Con este entendimiento, el signo del determinante de una base se puede utilizar para definir la noción de orientación en espacios euclídeos . El determinante de un conjunto de vectores es positivo si forman los vectores de un diestro sistema de coordenadas, y negativo si zurdo.
Determinantes se utilizan para calcular los volúmenes de cálculo de vectores : el valor absoluto del determinante de vectores reales es igual al volumen de la paralelepípedo atravesado por aquellos vectores. Como consecuencia, si el mapa lineal 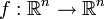 está representado por la matriz Y
está representado por la matriz Y 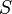 es cualquiera medible subconjunto de , Entonces el volumen de
es cualquiera medible subconjunto de , Entonces el volumen de 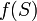 es dado por
es dado por 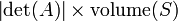 . Más generalmente, si el mapa lineal
. Más generalmente, si el mapa lineal 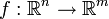 está representado por la
está representado por la 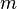 -by- matriz Y es cualquier subconjunto medible de
-by- matriz Y es cualquier subconjunto medible de 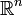 , Entonces el - volumen dimensional de es dado por
, Entonces el - volumen dimensional de es dado por 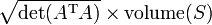 . Al calcular el volumen del tetraedro delimitada por cuatro puntos, que pueden ser utilizados para identificar líneas oblicuas.
. Al calcular el volumen del tetraedro delimitada por cuatro puntos, que pueden ser utilizados para identificar líneas oblicuas.
El volumen de cualquier tetraedro , dado sus vértices a, b, c, y d, es (1/6) · | det (a - b, b - c, c - d) |, o cualquier otra combinación de pares de vértices que forma un simplemente conectado gráfico.
Definición general y la computación
La definición del determinante viene de la siguiente teorema.
Teorema. Sea M n (K) denota el conjunto de todos 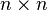 matrices sobre el campo K. Existe exactamente una función
matrices sobre el campo K. Existe exactamente una función
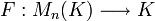
con las dos propiedades:
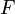 es alterno multilineal con respecto a las columnas;
es alterno multilineal con respecto a las columnas; 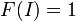 .
.
Uno puede entonces definir el determinante como la función única con las propiedades anteriores.
Para probar el teorema anterior, también se obtiene la Fórmula de Leibniz:
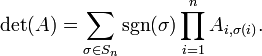
Aquí la suma se calcula sobre todas las permutaciones 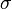 de los números de {1,2, ..., n} y
de los números de {1,2, ..., n} y 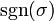 denota la firma de la permutación : 1 si es una incluso permutación y -1 si es impar.
denota la firma de la permutación : 1 si es una incluso permutación y -1 si es impar.
Esta fórmula contiene 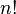 ( factorial ) sumandos, y es por lo tanto poco práctico utilizar para calcular determinantes para grandes .
( factorial ) sumandos, y es por lo tanto poco práctico utilizar para calcular determinantes para grandes .
Para las pequeñas matrices, se obtiene las siguientes fórmulas:
- si es una matriz de 1 por 1, a continuación,
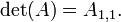
- si es una matriz de 2 por 2, a continuación,
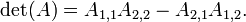
- para una matriz de 3 por 3 , La fórmula es más complicado:
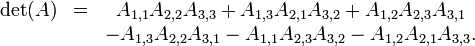
que toma la forma del esquema Sarrus ' .
En general, los factores determinantes se pueden calcular utilizando la eliminación gaussiana usando las siguientes reglas:
- Si es un matriz triangular, es decir,
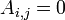 siempre que
siempre que 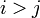 o, alternativamente, cada vez
o, alternativamente, cada vez 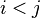 , A continuación,
, A continuación, 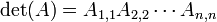 (El producto de las entradas diagonales de ).
(El producto de las entradas diagonales de ). - Si
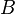 resultados de mediante el intercambio de dos filas o columnas, entonces
resultados de mediante el intercambio de dos filas o columnas, entonces 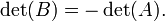
- Si resultados de multiplicando una fila o columna con el número de
 , A continuación,
, A continuación, 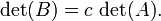
- Si resultados de mediante la adición de un múltiplo de una fila a otra fila, o un múltiplo de una columna a otra columna, a continuación,
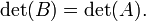
Explícitamente, comenzando con alguna matriz, utilizar los últimos tres reglas para convertirlo en una matriz triangular, a continuación, utilizar la primera regla para calcular su determinante.
También es posible ampliar un determinante a lo largo de una fila o columna usando La fórmula de Laplace, que es eficiente para matrices relativamente pequeñas. Para ello a lo largo de la fila 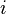 , Por ejemplo, escribimos
, Por ejemplo, escribimos
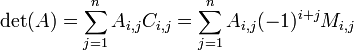
donde el 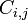 representar la matriz cofactores, es decir, es
representar la matriz cofactores, es decir, es 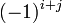 veces el menor
veces el menor 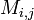 , Que es el determinante de la matriz que resulta de mediante la eliminación de la fila -ésimo y la
, Que es el determinante de la matriz que resulta de mediante la eliminación de la fila -ésimo y la  columna -th.
columna -th.
Ejemplo
Supongamos que queremos calcular el determinante de
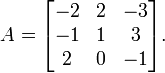
Podemos seguir adelante y utilizar la fórmula de Leibniz directamente:
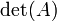

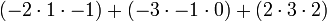
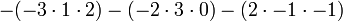
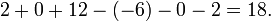
Alternativamente, podemos utilizar La fórmula de Laplace para ampliar el determinante a lo largo de una fila o columna. Lo mejor es elegir una fila o columna con muchos ceros, por lo que se expandirá a lo largo de la segunda columna:
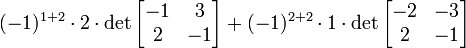
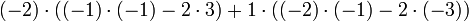
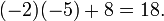
Una tercera forma (y el método de elección para matrices más grandes) implicarían el algoritmo de Gauss. Al hacer los cálculos a mano, a menudo se puede acortar cosas dramáticamente añadiendo inteligentemente múltiplos de columnas o filas a otras columnas o filas; esto no cambia el valor del determinante, pero puede crear entradas de cero lo que simplifica los cálculos posteriores. En este ejemplo, la adición de la segunda columna a la primera uno es especialmente útil:
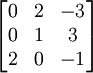
y este determinante puede ser expandido rápidamente a lo largo de la primera columna:
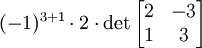
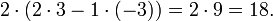
Propiedades
El determinante es un mapa multiplicativo en el sentido de que
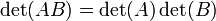 para todo n -by- n matrices y .
para todo n -by- n matrices y .
Esto se generaliza por el Fórmula de Cauchy-Binet a los productos de matrices no cuadradas.
Es fácil ver que 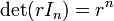 y por lo tanto
y por lo tanto
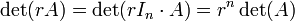 para todos -by- matrices y todo escalares
para todos -by- matrices y todo escalares  .
.
Una matriz sobre un anillo conmutativo R es invertible si y sólo si su determinante es una unidad en R. En particular, si A es una matriz sobre una campo como los reales o números complejos , entonces A es invertible si y sólo si det (A) no es cero. En este caso tenemos
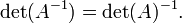
Expresado de otra manera: los vectores v 1, ..., v n en R n forman un base si y sólo si det (v 1, ..., v n) es distinto de cero.
Una matriz y su transponer tienen el mismo determinante:
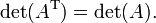
Los determinantes de una matriz compleja y de su transpuesta conjugada son conjugado:
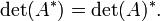
(Tenga en cuenta la transpuesta conjugada es idéntica a la transposición de una matriz real)
El determinante de una matriz exhibe las siguientes propiedades bajo transformaciones matriciales elementales de :
- Intercambiar filas o columnas multiplica el determinante por -1.
- Multiplicar una fila o columna multiplica por el factor determinante .
- Adición de un múltiplo de una fila o columna a otra deja el determinante sin cambios.
Así se desprende de la propiedad multiplicativa y los determinantes de la elementales matrices de transformación de la matriz.
Si y son similar, es decir, si existe una matriz invertible  de tal manera que =
de tal manera que = 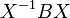 , Y luego por la propiedad multiplicativa,
, Y luego por la propiedad multiplicativa,
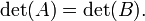
Esto significa que el determinante es una similitud invariante. Debido a esto, el determinante de alguna transformación lineal T: V → V para algunos de dimensión finita espacio vectorial V es independiente de la base de la V. La relación es de un solo sentido, sin embargo: existen matrices que tienen el mismo determinante, pero no son similares.
Si es un cuadrado -by- matriz con reales o complejos entradas y si λ 1, ..., λ n son los (complejo) valores propios de enumerados según sus multiplicidades algebraicas, luego
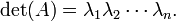
Esto se deduce del hecho de que siempre es similar a su Jordan forma normal, una matriz triangular superior con los valores propios de la diagonal principal.
Identidades útiles
Para m -by- n matriz A y m -by- n matriz B, se tiene
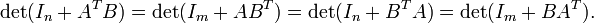
Una consecuencia de estas igualdades para el caso de (columna) vectores x e y
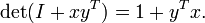
Y una versión generalizada de esta identidad
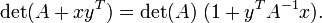
Las pruebas se pueden encontrar en .
Matrices Bloque
Supongamos,  son
son  matrices respectivamente. Entonces
matrices respectivamente. Entonces
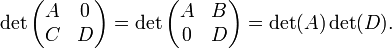
Esto puede ser (bastante) fácilmente visto desde por ejemplo la Fórmula de Leibniz. Empleando la siguiente identidad
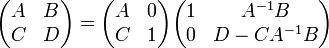
lleva a
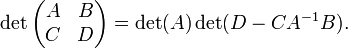
Identidad similares con 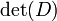 factorizada a cabo se puede derivar de forma análoga. Estas identidades se tomaron de .
factorizada a cabo se puede derivar de forma análoga. Estas identidades se tomaron de .
Si 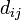 son matrices diagonales, entonces
son matrices diagonales, entonces
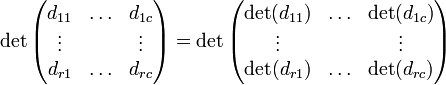
Este es un caso especial del teorema publicado en .
Relación con el rastro
A partir de esta conexión entre el determinante y los valores propios, se puede derivar una conexión entre el función de rastreo, la función exponencial, y el determinante:
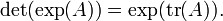
Realizar la sustitución 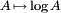 en los rendimientos de ecuaciones anteriores
en los rendimientos de ecuaciones anteriores
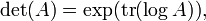
que está estrechamente relacionado con el Determinante Fredholm. Del mismo modo,
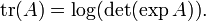
Para n -by- n matrices están las relaciones:
- Caso n = 1:
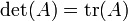
- Caso n = 2:
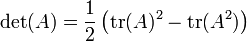
- Caso n = 3:
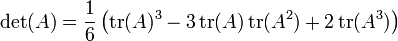
- Caso n = 4:
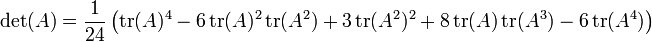
que están estrechamente relacionados con Identidades de Newton.
Derivado
El determinante de matrices cuadradas reales es una función polinómica de 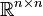 a
a 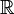 , Y como tal, está en todas partes diferenciables . Su derivado puede expresarse utilizando La fórmula de Jacobi:
, Y como tal, está en todas partes diferenciables . Su derivado puede expresarse utilizando La fórmula de Jacobi:
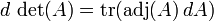
donde adj (A) denota la adjugate de A. En particular, si A es invertible, tenemos
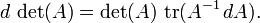
En forma de componentes, estos son
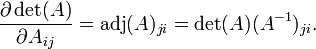
Cuando  es un pequeño número de éstos son equivalentes a
es un pequeño número de éstos son equivalentes a
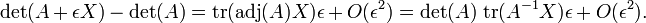
El caso especial de que es igual a la matriz identidad 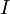 rendimientos
rendimientos
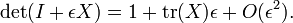
Una propiedad útil en el caso de 3 x 3 matrices es la siguiente:
A puede escribirse como 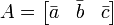 donde
donde 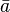 ,
, 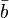 ,
, 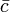 son vectores, entonces el gradiente de más de uno de los tres vectores se puede escribir como el producto cruzado de los otros dos:
son vectores, entonces el gradiente de más de uno de los tres vectores se puede escribir como el producto cruzado de los otros dos:
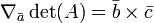
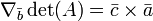
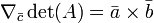
Formulación abstracta
Un n × n matriz cuadrada A puede ser pensado como la representación de una coordenada transformación lineal de un n-dimensional espacio vectorial V. Dado cualquier transformación lineal
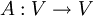
podemos definir el determinante de A como el determinante de cualquier representación matricial de A. Esto es un noción bien definida (es decir, independiente de la elección de base), ya que el determinante es invariante bajo transformaciones de semejanza.
Como era de esperar, es posible definir el determinante de una transformación lineal de manera coordinar libre. Si V es un espacio vectorial n-dimensional, entonces uno puede construir su cima exterior Λ potencia n V. Este es un espacio vectorial unidimensional cuyos elementos están escritos
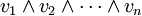
donde cada v i es un vector en V y la producto exterior ∧ es antisimétrica (es decir, u ∧ u = 0). Cualquier transformación lineal A: V → V induce una transformación lineal de Λ n V de la siguiente manera:
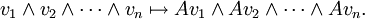
Desde Λ V n es unidimensional esta operación se acaba de multiplicación por algunos escalar que depende de una. Esta escalar se llama el determinante de A. Es decir, definimos det (A) por la ecuación
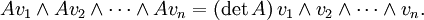
Se puede comprobar que esta definición está de acuerdo con la definición de coordenadas dependiente dado anteriormente.
Aplicación algorítmica
- El método ingenua de la aplicación de un algoritmo para calcular el determinante es el uso de la fórmula de Laplace para la expansión por cofactores. Este enfoque es extremadamente ineficiente en general, sin embargo, ya que es de orden n! (N factorial ) para una matriz n × n M.
- Una mejora de orden n 3 se puede lograr mediante el uso de Descomposición LU escribir M = LU para triangular matrices L y U. Ahora, det M = det LU = det L det U, y desde L y U son triangulares el determinante de cada uno es simplemente el producto de sus elementos diagonales. Alternativamente, se puede realizar la Descomposición de Cholesky si es posible o la Descomposición QR y encontrar el determinante de una manera similar.
- Dado que la definición del determinante no necesita divisiones, surge una pregunta: ¿algoritmos rápidos existir que no necesitan divisiones? Esto es especialmente interesante para las matrices sobre anillos. Algoritmos hecho con tiempo de ejecución proporcional an 4 existir. Una algoritmo de Mahajan y Vinay, y Berkowitz se basa en caminatas ordenadas cerrados (corto Clow). Se calcula más productos que la definición determinante requiere, pero algunos de estos productos cancelar y la suma de estos productos se puede calcular de manera más eficiente. El algoritmo final se parece mucho a un producto iterativa de las matrices triangulares.
- Lo que no se discute a menudo es el llamado "complejidad poco" del problema, es decir, la cantidad de bits de precisión que necesita para almacenar los valores intermedios. Por ejemplo, usando eliminación de Gauss , se puede reducir la matriz a la forma triangular superior, luego multiplicar la diagonal principal de obtener el determinante (este es esencialmente un caso especial de la descomposición LU como antes), pero un cálculo rápido mostrará que el bit tamaño de valores intermedios potencialmente podría llegar a ser exponencial. Se podría hablar de cuándo es adecuado para redondear valores intermedios, pero de una manera elegante de calcular el determinante utiliza el Bareiss algoritmo, un método exacto por división basa en Identidad de Sylvester para dar un tiempo de ejecución de orden n 3 y complejidad poco más o menos el tamaño de bits de las entradas originales en los tiempos de la matriz n.
Historia
Históricamente, los factores determinantes fueron considerados antes de matrices. Originalmente, un determinante se define como una propiedad de un sistema de ecuaciones lineales . El determinante "determina" si el sistema tiene una solución única (que se produce precisamente si el determinante es distinto de cero). En este sentido, los factores determinantes se utilizaron por primera vez en el libro de texto de matemáticas BC chino del siglo tercero Los nueve capítulos en el arte matemático. En Europa, de dos en dos factores determinantes fueron considerados por Cardano al final del siglo 16 y los más grandes por Leibniz y, en Japón, por Seki cerca de 100 años más tarde. Cramer (1750) añade a la teoría, el tratamiento del tema en relación con sistemas de ecuaciones. La ley recurrente fue anunciado por primera vez por Bézout (1764).
Fue Vandermonde (1771) que primero determinantes reconocido como funciones independientes. Laplace (1772) dio el método general de ampliar un factor determinante en términos de su complementaria menores: Vandermonde ya había dado un caso especial. Inmediatamente después, Lagrange (1773) trataron determinantes del segundo y tercer orden. Lagrange fue el primero en aplicar determinantes a las preguntas teoría de la eliminación; demostró muchos casos especiales de identidades generales.
Gauss (1801) hizo el siguiente avance. Como Lagrange, hizo mucho uso de los determinantes en la teoría de los números . Se introdujo la palabra determinantes (Laplace había usado resultante), aunque no en el presente significación, sino más bien como aplicada a la discriminante de una cuántico. Gauss también llegó a la noción de (inversos) determinantes recíprocos, y estuvo muy cerca del teorema de la multiplicación.
El siguiente factor de importancia es Binet (1811, 1812), que declaró formalmente el teorema relacionada con el producto de dos matrices de m columnas y n filas, que para el caso especial de m = n reduce con el teorema de la multiplicación. En el mismo día ( 30 de noviembre de 1812 ) que Binet presentó su documento a la Academia, Cauchy también presentó uno sobre el tema. (Ver Fórmula de Cauchy-Binet.) En este usó la palabra determinante en su sentido actual, resumida y simplificada de lo que entonces se conocía sobre el tema, mejoró la notación, y le dio el teorema de multiplicación con una prueba más satisfactoria que Binet. Con él comienza la teoría en su generalidad.
La siguiente figura importante era Jacobi (desde 1827). Él temprana utilizó el determinante funcional que Sylvester más tarde llamó la Jacobiano, y en sus memorias en Crelle para 1841 especialmente trata este tema, así como la clase de funciones que Sylvester ha llamado alternantes alterna. Sobre el momento de las últimas memorias de Jacobi, Sylvester (1839) y Cayley comenzó su trabajo.
El estudio de las formas especiales de los determinantes ha sido el resultado natural de la finalización de la teoría general. Determinantes simetría axial han sido estudiados por Lebesgue, Hesse, y Silvestre; determinantes persymmetric por Sylvester y Hankel; circulants por Catalán, Spottiswoode, Glaisher, y Scott; determinantes de sesgo y Pfaffians, en relación con la teoría de la transformación ortogonal, por Cayley; continuants por Sylvester; Wronskians (llamado así por Muir) por Christoffel y Frobenius; determinantes compuestos por Sylvester, Reiss, y Picquet; Jacobianos y Arpilleras por Sylvester; y determinantes gauche simétricos por Trudi. De los libros de texto sobre el tema Spottiswoode fue la primera. En Estados Unidos, Hanus (1886), Weld (1893), y Muir / Metzler (1933), publicado tratados.