

Protéine
Contexte des écoles Wikipédia
Enfants SOS ont produit une sélection d'articles de wikipedia pour les écoles depuis 2005. Tous les enfants disponibles pour le parrainage de SOS Enfants des enfants sont pris en charge dans une maison de famille près de la charité. Lire la suite ...
Protéines (pron .: / /; On connaît également que des polypeptides) sont des composés organiques en acides aminés disposés en une chaîne linéaire et pliées dans une globulaire ou forme fibreuse. Les acides aminés dans un polymère sont reliés entre eux par le des liaisons peptidiques entre les carboxyles et amino des groupes d'acide aminé adjacent résidus. Le séquence d'acides aminés dans une protéine est définie par la une séquence de gène, qui est codée dans le code génétique . En général, le code génétique précise 20 acides aminés standards; toutefois, dans certains organismes du code génétique peut comprendre sélénocystéine et dans certains archaea- pyrrolysine. Peu de temps après ou même pendant la synthèse, les résidus dans une protéine sont souvent modifiés chimiquement par modification post-traductionnelle, qui modifie les propriétés physiques et chimiques, le pliage, la stabilité, l'activité, et, finalement, la fonction des protéines. Les protéines peuvent aussi travailler ensemble pour parvenir à une fonction particulière, et ils associent souvent pour former stable complexes.
Une des caractéristiques les plus distinctives de polypeptides est leur capacité à se replier dans un état globulaire ou «structure». La mesure dans laquelle les protéines se replient en une structure définie est très variable. Certaines protéines se plient en une structure très rigide avec de petites fluctuations et sont donc considérés comme structure unique. D'autres protéines subissent des réarrangements de grands une conformation à l'autre. Ce changement de conformation est souvent associée à une signalisation événement. Ainsi, la structure d'une protéine servant de support à travers laquelle une ou l'autre de réguler la fonction d'une protéine ou de l'activité d'une enzyme. Pas toutes les protéines nécessitant un processus de pliage pour fonctionner, comme une fonction dans un état déplié.
Comme d'autres biologique des macromolécules telles que polysaccharides et acides nucléiques, protéines sont des éléments essentiels d'organismes et participez dans pratiquement tous les processus au sein des cellules . De nombreuses protéines sont enzymes qui catalysent les réactions biochimiques et sont vitales pour métabolisme. Les protéines ont également des fonctions structurelles ou mécaniques, tels que actine et la myosine dans le muscle et les protéines dans le cytosquelette, qui forment un système de échafaudage qui maintient la forme des cellules. D'autres protéines sont importantes la signalisation cellulaire, des réponses immunitaires , l'adhésion cellulaire, et la cycle cellulaire. Les protéines sont également nécessaires dans l'alimentation des animaux, puisque les animaux ne peuvent pas synthétiser tous les acides aminés dont ils ont besoin et doivent obtenir acides aminés essentiels de la nourriture. Grâce au processus de la digestion, les animaux se décomposent protéines ingérées en acides aminés libres qui sont ensuite utilisés dans le métabolisme.
Les protéines ont d'abord été décrits par la Chimiste hollandais Johannes Gerhardus Mulder et nommé par le chimiste suédois Jöns Jakob Berzelius en 1838. Les premiers scientifiques nutritionnels tels que l'allemand Carl von Voit croit que la protéine était le nutriment le plus important pour le maintien de la structure du corps, car il a été généralement admis que «la chair fait chair." Le rôle central des protéines telles que des enzymes dans les organismes vivants n'a cependant pas été pleinement apprécié jusqu'à 1926, lorsque James B. Sumner a montré que l'enzyme uréase est en effet une protéine. La première protéine soit séquencé était l'insuline , par Frederick Sanger , qui a remporté le prix Nobel pour cette réalisation en 1958. La première structures de protéines à résoudre étaient hémoglobine et la myoglobine, par Max Perutz et Sir John Cowdery Kendrew, respectivement, en 1958. Les structures tridimensionnelles des deux protéines ont d'abord été déterminés par L'analyse par diffraction de rayons X; Perutz et Kendrew partagé le 1962 Prix Nobel de chimie pour ces découvertes. Les protéines peuvent être purifiée à partir d'autres composants cellulaires en utilisant une variété de techniques telles que ultracentrifugation, précipitation, électrophorèse et chromatographie ; l'avènement de génie génétique a permis un certain nombre de méthodes pour faciliter la purification. Des procédés couramment utilisés pour étudier la structure et la fonction des protéines comprennent immunohistochimie, mutagenèse dirigée, résonance magnétique nucléaire et spectrométrie de masse .
Biochimie
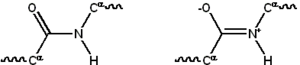
La plupart des protéines sont linéaires polymères construits à partir de la série de jusqu'à 20 différent -α- L des acides aminés . Tous les acides aminés possèdent des caractéristiques structurelles communes, comprenant une α-atome de carbone auquel un groupe amino groupe, un carboxyle groupe, et une variable chaîne latérale sont lié . Seulement proline diffère de cette structure de base, car il contient un cycle inhabituel pour le groupe amine N-fin, ce qui force le fragment amide CO-NH dans une conformation fixe. Les chaînes latérales des acides aminés classiques, décrites dans le liste des acides aminés standards, avoir une grande variété de structures et propriétés chimiques; ce est l'effet combiné de l'ensemble des chaînes latérales d'acides aminés dans une protéine qui détermine finalement la structure en trois dimensions et de sa réactivité chimique.
 |  | |
La structure chimique de la liaison peptidique (à gauche) et d'une liaison peptidique entre leucine et thréonine (à droite) | ||
Les acides aminés dans une chaîne polypeptidique sont liés par des liaisons peptidiques. Une fois lié à la chaîne de protéine, un acide aminé particulier est appelé un résidu, et la série liée de carbone, d'azote et des atomes d'oxygène sont connus en tant que chaîne principale ou squelette protéique. La liaison peptidique a deux formes de résonance qui contribuent un certain caractère de double liaison et empêcher une rotation autour de son axe, de sorte que les atomes de carbone alpha sont plus ou moins coplanaires. Les deux autres les angles dièdres de la liaison peptidique déterminer la forme locale assumée par le squelette protéique. L'extrémité de la protéine avec un groupe carboxyle libre est connue comme la C-terminale ou carboxy-terminale, tandis que l'extrémité avec un groupe amino libre est connue comme la N-terminale ou amino-terminale.
La protéine de mots, polypeptide, et peptide sont un peu ambigus et peuvent se chevaucher dans un sens. La protéine est généralement utilisé pour désigner la molécule biologique complet dans une étable conformation, alors que le peptide est généralement réservé pour une courte oligomères d'acide aminé manque souvent une structure tridimensionnelle stable. Cependant, la frontière entre les deux ne est pas bien défini et se trouve généralement près de 20 à 30 résidus. Polypeptide peut se référer à toute chaîne linéaire simple des acides aminés, généralement indépendamment de la longueur, mais implique souvent une absence de sens conformation.
Synthèse

Les protéines sont assemblées à partir des acides aminés en utilisant les informations codées dans gènes. Chaque protéine a sa propre séquence d'acides aminés unique qui est spécifié par le séquence de nucleotides du gène codant pour cette protéine. Le code génétique est un ensemble de trois ensembles de nucléotides appelés codons et chaque combinaison de trois nucleotides désigne un acide aminé, par exemple août ( adenine- uracil- guanine) est le code pour méthionine. Étant donné que l'ADN contient quatre nucleotides, le nombre total de codons possibles est 64; par conséquent, il existe une certaine redondance dans le code génétique, certains acides aminés spécifiés par plus d'un codon. Les gènes codés dans l'ADN sont tout d'abord transcrit en pré- L'ARN messager (ARNm) par des protéines telles que ARN polymérase. La plupart des organismes traiter ensuite le pré-ARNm (aussi connu comme un transcrit primaire) en utilisant différentes formes de modification post-transcriptionnelle pour former l'ARNm mature, qui est ensuite utilisé comme matrice pour la synthèse de protéine par la ribosome. En procaryotes l'ARNm peut soit être utilisé dès qu'il est produit, ou être lié par un ribosome après avoir écarté de la nucléoïde. En revanche, les eucaryotes font ARNm dans le noyau de la cellule et ensuite translocation à travers la dans la membrane nucléaire cytoplasme, où la synthèse des protéines a alors lieu. Le taux de synthèse des protéines est plus élevée que chez les procaryotes et les eucaryotes peut atteindre jusqu'à 20 acides aminés par seconde.
Procédé de synthèse d'une protéine à partir d'une matrice d'ARNm est connu comme traduction. L'ARNm est chargé sur le ribosome et trois nucleotides est lue à la fois par chaque codon correspondant à sa appariement de bases situé sur un anticodon transférer une molécule d'ARN, qui porte l'acide aminé correspondant au codon il reconnaît. L'enzyme aminoacyl ARNt synthétase "frais" l'ARNt molécules avec les acides aminés corrects. Le polypeptide en croissance est souvent appelée la chaîne naissante. Les protéines sont toujours biosynthétisées à partir de N-terminale à l'extrémité C-terminale.
La taille d'une protéine synthétisée peut être mesurée par le nombre d'acides aminés qu'il contient et par sa totale masse moléculaire , qui est normalement rapporté en unités de daltons (synonyme de unités de masse atomique), ou le dérivé de l'unité kilodaltons (kDa). levure de protéines sont une moyenne de 466 acides aminés de long et de 53 kDa de la masse. Les protéines connues les plus importants sont le titins, une composante de la muscle sarcomère, avec une masse moléculaire de près de 3 000 kDa et une longueur totale de près de 27 000 acides aminés.
La synthèse chimique
Courts protéines peuvent également être synthétisés chimiquement par une famille de procédés connus en tant que la synthèse des peptides, qui se appuient sur des techniques de synthèse organiques tels que ligature chimique pour produire des peptides avec un rendement élevé. Synthèse chimique permet l'introduction d'acides aminés non naturels dans les chaînes de polypeptides, tels que la fixation de sondes fluorescentes aux acides des chaînes latérales d'acides. Ces procédés sont utiles dans le laboratoire de biochimie et biologie cellulaire, bien que généralement pas pour des applications commerciales. La synthèse chimique est inefficace pour des polypeptides plus longs à environ 300 acides aminés, et les protéines synthétisées peuvent pas facilement assumer leur native structure tertiaire. La plupart des méthodes de synthèse chimique procèdent d'extrémité C-terminale à N-terminale, opposée à la réaction biologique.
Structure

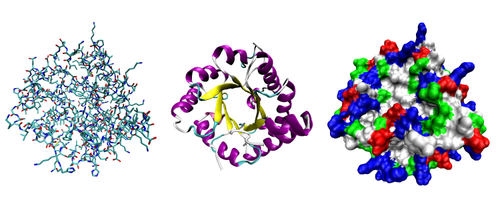
La plupart des protéines plier en trois dimensions des structures uniques. La forme dans laquelle une protéine naturellement plis est connu comme son conformation native. Bien que de nombreuses protéines peuvent se replier sans aide, tout simplement à travers les propriétés chimiques de leurs acides aminés, d'autres nécessitent l'aide d'moléculaire chaperons se replier dans leurs états indigènes. Biochimistes se réfèrent souvent à quatre aspects distincts de la structure d'une protéine:
- Structure primaire: le séquence d'acides aminés.
- Structure secondaire: répéter régulièrement les structures locales stabilisés par des liaisons hydrogène. Les exemples les plus courants sont le hélice alpha, feuille bêta et tourne. Étant donné que les structures secondaires sont locaux, de nombreuses régions de structure secondaire différente peuvent être présents dans la même molécule de protéine.
- La structure tertiaire: la forme générale d'une seule molécule de protéine; la relation spatiale entre les structures secondaires les unes aux autres. Structure tertiaire est généralement stabilisé par des interactions non locales, le plus souvent la formation d'une noyau hydrophobe, mais aussi par des ponts de sel, des liaisons hydrogène, ponts disulfures, et même modifications post-traductionnelles. Le terme «structure tertiaire" est souvent utilisé comme synonyme de la bergerie terme. La structure tertiaire est ce qui contrôle la fonction de base de la protéine.
- Structure quaternaire: la structure formée par plusieurs molécules de protéine (chaînes polypeptidiques), habituellement appelée sous-unités protéiques dans ce contexte, qui fonctionnent comme un seul complexe protéique.
Les protéines ne sont pas entièrement molécules rigides. En plus de ces niveaux de la structure, les protéines peuvent se déplacer entre plusieurs structures liées pendant qu'ils exercent leurs fonctions. Dans le cadre de ces réarrangements fonctionnels, ces structures tertiaires ou quaternaires sont habituellement appelés " conformations ", et les transitions entre elles sont appelées des changements conformationnels. De telles modifications sont souvent induites par la liaison d'un molécule de substrat à une enzyme de site actif, ou la région physique de la protéine qui participe à la catalyse chimique. Dans les protéines de la solution subir également des variations dans la structure par vibration thermique et la collision avec d'autres molécules.

Les protéines peuvent être informelle divisés en trois classes principales, qui sont en corrélation avec les structures tertiaires typiques: les protéines globulaires, des protéines fibreuses, et des protéines membranaires. Presque toutes les protéines globulaires sont solubles et beaucoup sont des enzymes. Protéines fibreuses sont souvent structurelles, telles que le collagène, le composant majeur du tissu conjonctif, ou kératine, le composant protéique des cheveux et des ongles. Les protéines membranaires servent souvent des récepteurs ou des canaux pour fournir polaire ou des molécules chargées de passer à travers le membrane cellulaire.
Un cas particulier de liaisons hydrogène intramoléculaires au sein de protéines, mal protégé contre les attaques de l'eau et donc la promotion de leur propre la déshydratation, sont appelés dehydrons.
Détermination de la structure
Découverte de la structure tertiaire d'une protéine, ou de la structure quaternaire de ses complexes, peuvent fournir des indices importants sur la façon dont la protéine exerce sa fonction. Méthodes expérimentales communes de détermination de la structure comprennent Cristallographie aux rayons X et Spectroscopie RMN, qui peuvent tous deux produire de l'information au atomique résolution. Cependant, des expériences de RMN sont en mesure de fournir des informations à partir de laquelle un sous-ensemble de distances entre paires d'atomes peut être estimée, et les conformations possibles finales pour une protéine sont déterminées par résolution d'un problème de géométrie à distance. Interférométrie à double polarisation est une méthode d'analyse quantitative de mesure de la protéine globale conformation et changements conformationnels dus à des interactions ou autre stimulus. Dichroïsme circulaire est une autre technique de laboratoire pour déterminer la composition interne feuille / hélicoïdal bêta de protéines. cryomicroscopie électronique est utilisé pour produire à faible résolution des informations structurales sur de très grands complexes de protéines, y compris assemblés virus ; une variante appelée cristallographie électronique peut également produire de l'information à haute résolution, dans certains cas, en particulier pour cristaux bidimensionnelles de protéines membranaires. Résolu structures sont habituellement déposés dans le Protein Data Bank (PDB), une ressource librement accessible à partir de laquelle les données structurelles sur des milliers de protéines peuvent être obtenues sous la forme de coordonnées cartésiennes de chaque atome dans la protéine.
Beaucoup plus de séquences de gènes sont connus que des structures de protéines. En outre, l'ensemble des structures résolues est sollicité vers protéines qui peuvent être facilement soumises à des conditions requises en Cristallographie aux rayons X, l'une des principales méthodes de détermination de la structure. En particulier, les protéines globulaires sont relativement faciles à cristalliser en vue de cristallographie aux rayons X. Les protéines membranaires, en revanche, sont difficiles à cristalliser et sont sous-représentées dans l'APB. Initiatives de génomique structurale ont tenté de remédier à ces carences en résolvant systématiquement structures représentatives des principales catégories de pliage. Protéines méthodes de prédiction de la structure tentent de fournir un moyen de génération d'une structure plausible pour des protéines dont les structures ne ont pas été déterminée expérimentalement.
Fonctions cellulaires
Les protéines sont les principaux acteurs au sein de la cellule, a déclaré à l'accomplissement des tâches spécifiées par l'information codée dans les gènes. A l'exception de certains types de ARN, la plupart des autres molécules biologiques sont des éléments relativement inertes sur lequel agissent les protéines. Les protéines constituent la moitié du poids sec d'un cellule d 'Escherichia coli, alors que d'autres macromolécules telles que l'ADN et l'ARN ne représentent que 3% et 20%, respectivement. L'ensemble des protéines exprimées dans une cellule ou un type cellulaire particulier est connu en tant que protéome.

La caractéristique principale de protéines qui permet aussi leur ensemble varié de fonctions est leur capacité à se lier d'autres molécules spécifiquement et étroitement. La région de la protéine responsable de la liaison à une autre molécule est connue sous le site de liaison et est souvent une dépression ou «poche» sur la surface moléculaire. Cette capacité de liaison est médiée par la structure tertiaire de la protéine, qui définit la poche de site de liaison, et par les propriétés chimiques des chaînes latérales des acides aminés environnants. La liaison aux protéines peut être extrêmement serré et spécifique; par exemple, la protéine d'inhibiteur de ribonucléase humaine se lie à angiogénine avec un sous-femtomolaire constante de dissociation (<10 -15 M) mais ne se lie pas du tout à son homologue amphibie onconase (> 1 M). Changements chimiques extrêmement mineures telles que l'ajout d'un groupe méthyle unique à un partenaire de liaison peuvent parfois suffire à éliminer presque contraignant; par exemple, la aminoacyl ARNt synthétase spécifique de l'acide aminé valine discriminatoire à l'égard de la chaîne latérale très similaire de l'acide aminé isoleucine.
Les protéines peuvent se lier à d'autres protéines ainsi que de substrats à petites molécules. Lorsque les protéines se lient spécifiquement à d'autres copies de la même molécule, ils peuvent oligomériser pour former des fibrilles; ce processus se produit souvent dans les protéines structurelles qui se composent de monomères globulaires qui se auto-associer pour former des fibres rigides. Les interactions protéine-protéine régulent également l'activité enzymatique, contrôlent la progression à travers le cycle cellulaire, et permettre à l'ensemble de grande complexes de protéines qui effectuent de nombreuses réactions étroitement liés avec une fonction biologique commune. Les protéines peuvent également se lier à, ou même être intégré dans les membranes cellulaires. La capacité des partenaires de liaison pour induire des changements conformationnels de protéines permet la construction d'une très grande complexité réseaux de signalisation. Il est important, que les interactions entre protéines sont réversibles, et dépendent fortement de la disponibilité des différents groupes de protéines de partenaires pour former des agrégats qui sont capables de réaliser des ensembles discrets de la fonction, l'étude des interactions entre protéines spécifiques est une clé pour comprendre les aspects importants de la fonction cellulaire, et finalement les propriétés qui le distinguent des types cellulaires particuliers.
Enzymes
Les plus connus rôle des protéines dans la cellule est aussi des enzymes qui catalysent des réactions chimiques. Les enzymes sont habituellement hautement spécifique et accélérer seulement une ou quelques réactions chimiques. Les enzymes effectuent la plupart des réactions impliquées dans métabolisme, ainsi que la manipulation de l'ADN dans des procédés tels que réplication de l'ADN, la réparation d'ADN , et transcription. Certaines enzymes agissent sur d'autres protéines pour ajouter ou supprimer des groupes chimiques dans un processus connu sous le nom modification post-traductionnelle. Environ 4.000 réactions sont connues pour être catalysée par des enzymes. L'accélération de la vitesse conférée par catalyse enzymatique est souvent énorme-jusqu'à 10 -fois 17 augmentation de la fréquence au-dessus de la réaction non catalysée dans le cas de décarboxylase orotate (78 millions d'années sans l'enzyme, 18 millisecondes avec l'enzyme).
Les molécules liées et exécutées par des enzymes sont appelés substrats. Bien que les enzymes peuvent être constituées de plusieurs centaines d'acides aminés, ce est généralement seulement une petite fraction des résidus qui entrent en contact avec le substrat, et une fraction encore plus petite trois ou quatre résidus en moyenne, qui sont directement impliqués dans la catalyse. La région de l'enzyme qui se lie au substrat et qui contient des résidus catalytiques est connue sous le nom site actif.
la signalisation cellulaire et la liaison du ligand

Plusieurs protéines sont impliquées dans le processus de la signalisation cellulaire et la transduction de signal. Certaines protéines telles que l'insuline , sont des protéines extracellulaires qui transmettent un signal de la cellule dans laquelle ils ont été synthétisés à d'autres cellules dans la lointaine tissus. D'autres sont les protéines membranaires qui agissent comme récepteurs dont la fonction principale est de lier une molécule de signalisation et induisent une réponse biochimique dans la cellule. De nombreux récepteurs ont un site de liaison exposée sur la surface des cellules et un domaine effecteur dans la cellule, qui peut avoir une activité enzymatique ou peut subir un changement de conformation détecté par d'autres protéines dans la cellule.
Les anticorps sont des composants protéiques de le système immunitaire adaptatif dont la fonction principale est de lier antigènes, ou des substances étrangères dans le corps, et les cibler pour la destruction. Les anticorps peuvent être sécrétée dans le milieu extracellulaire ou ancrée dans la membrane des spécialisé cellules B connu sous le nom les cellules plasmatiques. Considérant que les enzymes sont limités dans leur affinité de liaison pour leurs substrats par la nécessité d'effectuer leur réaction, les anticorps ne ont pas de telles contraintes. L'affinité de liaison d'un anticorps à son objectif est extraordinairement élevé.
Beaucoup de protéines de transport ligands se lient notamment petites biomolécules et les transportent à d'autres endroits dans le corps d'un organisme multicellulaire. Ces protéines doivent avoir une affinité de liaison élevée lorsque leur ligand est présent dans des concentrations élevées, mais doit également libérer le ligand lorsqu'il est présent en faibles concentrations dans les tissus cibles. L'exemple type d'une protéine de liaison de ligand est hémoglobine qui transporte l'oxygène à partir de la poumons à d'autres organes et tissus dans tous les vertébrés et compte près homologues dans chaque biologique royaume. Les lectines sont des protéines de liaison à sucre qui sont hautement spécifiques pour les fragments de sucre. Les lectines jouent généralement un rôle dans biologique phénomènes de reconnaissance impliquant des cellules et des protéines. Récepteurs et hormones sont des protéines de liaison hautement spécifiques.
protéines transmembranaires peuvent également servir de protéines de transport de ligand qui modifient la la perméabilité de la membrane cellulaire à petites molécules et ions. La membrane seul a coeur hydrophobe à travers laquelle molécules polaires ou chargés ne peut pas diffuser. Les protéines membranaires contiennent des canaux internes qui permettent de telles molécules d'entrer et de sortir de la cellule. Beaucoup protéines de canaux ioniques sont spécialisées pour sélectionner seulement un ion particulier; par exemple, de potassium et de sodium sont souvent discriminatoires canaux pour une seule des deux ions.
Protéines structurales
Protéines structurales confèrent rigidité et la rigidité des composants biologiques contraire fluides. La plupart des protéines structurales sont des protéines fibreuses; par exemple, actine et tubuline sont globulaire soluble et sous forme de monomères, mais polymériser pour former des longues fibres rigides qui composent le cytosquelette, ce qui permet à la cellule de maintenir sa forme et sa taille. Collagène et élastine sont des composantes essentielles de tissu conjonctif tel que cartilage, et kératine se trouve dans des structures dures ou filamenteux tels que cheveux, ongles, plumes , sabots, et certains coquilles d'animaux.
D'autres protéines qui servent des fonctions structurelles sont protéines motrices telles que myosine, kinésine, et dynéine, qui sont capables de générer des forces mécaniques. Ces protéines sont essentielles pour cellulaire motilité des organismes unicellulaires et la spermatozoïdes de nombreux organismes multicellulaires qui reproduisent sexuellement. Ils génèrent également les forces exercées par traitance muscles.
Méthodes d'étude
Comme certains d'entre molécules biologiques les plus couramment étudiées, les activités et les structures de protéines sont examinés à la fois in vitro et in vivo Des études in vitro de protéines purifiées dans des environnements contrôlés sont utiles pour apprendre une protéine exerce sa fonction:. par exemple, la cinétique enzymatique études explorent la mécanisme chimique de l'activité catalytique d'une enzyme et son affinité relative pour différentes molécules de substrat possibles. En revanche, dans des expériences in vivo sur les activités de protéines dans les cellules ou même au sein des organismes entiers peuvent fournir des informations complémentaires sur l'endroit où une des fonctions des protéines et comment il est réglementé.
La purification des protéines
Pour effectuer L'analyse in vitro, une protéine doit être purifié loin des autres composants cellulaires. Ce processus commence habituellement par la lyse des cellules, dans lequel la membrane de la cellule est interrompue et son contenu interne libéré dans une solution connue en tant que lysat brut. Le mélange résultant peut être purifié en utilisant ultracentrifugation, qui fractionne les différents composants cellulaires en fractions contenant des protéines solubles; membrane lipides et des protéines; cellulaire organelles, et acides nucléiques. La précipitation par un procédé connu sous le nom relargage peut concentrer les protéines de ce lysat. Différents types de chromatographie sont ensuite utilisés pour isoler la ou les protéines d'intérêt en fonction des propriétés telles que le poids moléculaire, charge nette et affinité de liaison. Le niveau de purification peut être contrôlée en utilisant divers types de électrophorèse sur gel si le poids moléculaire de la protéine souhaitée et point isoélectrique sont connus, par spectroscopie si la protéine a des caractéristiques spectroscopiques distinctes, ou en des dosages d'enzymes si la protéine a une activité enzymatique. En outre, les protéines peuvent être isolés selon leur charge à l'aide électrofocalisation.
Pour les protéines naturelles, une série d'étapes de purification peut être nécessaire d'obtenir la protéine suffisamment pur pour les applications de laboratoire. Pour simplifier ce processus, génie génétique est souvent utilisé pour ajouter des fonctionnalités chimiques aux protéines qui les rendent plus facile pour purifier sans affecter leur structure ou l'activité. Ici, un «tag» consistant en une séquence d'acides aminés spécifique, souvent une série de résidus histidine (a » His-tag "), est fixé à une extrémité de la protéine. Par conséquent, lorsque le lysat est passée sur une colonne de chromatographie contenant du nickel , les résidus d'histidine ligaturer le nickel et le fixent à la colonne tandis que les composants non marqués de l'étape de lysat sans entrave. Un certain nombre de marqueurs différents ont été développés pour aider les chercheurs à purifier des protéines spécifiques à partir de mélanges complexes.
Localisation cellulaire

L'étude in vivo de protéines est souvent concernés par la synthèse et la localisation de la protéine dans la cellule. Bien que de nombreuses protéines intracellulaires sont synthétisées dans le cytoplasme et membranaires ou des protéines sécrétées dans le réticulum endoplasmique, les détails de la façon dont les protéines sont ciblé vers les organites spécifiques ou des structures cellulaires est souvent difficile. Une technique utile pour l'évaluation de la localisation cellulaire utilise le génie génétique pour exprimer dans une cellule un Protéine de fusion ou chimère consistant en la protéine naturelle d'intérêt lié à un " journaliste "tels que la protéine fluorescente verte (GFP). La position de la protéine fusionnée dans la cellule peut être proprement et efficacement visualisée en utilisant microscopie, comme le montre la figure ci-contre.
D'autres méthodes pour élucider la localisation cellulaire des protéines nécessite l'utilisation de marqueurs compartimentaux connus pour des régions comme l'ER, le, lysosomes / vacuoles, les mitochondries, les chloroplastes, membrane plasmique Golgi, etc. Avec l'utilisation de fluorescence marqués versions de ces marqueurs ou des anticorps dirigés contre des marqueurs connus, il devient beaucoup plus simple pour identifier la localisation d'une protéine d'intérêt. Par exemple, immunofluorescence indirecte permettra de fluorescence colocalisation et la démonstration de l'emplacement. Les colorants fluorescents sont utilisés pour marquer des compartiments cellulaires dans un but similaire.
D'autres possibilités existent, aussi bien. Par exemple, immunohistochimie utilise généralement un anticorps dirigé contre une ou plusieurs protéines d'intérêt qui sont conjugués à des enzymes donnant des signaux non luminescent ou chromogènes qui peuvent être comparées entre les échantillons, ce qui permet à des informations de localisation. Une autre technique est applicable cofractionation dans le saccharose (ou autre matériau) en utilisant des gradients centrifugation isopycnique. Bien que cette technique ne prouve pas colocalisation d'un compartiment de densité connue et la protéine d'intérêt, elle augmente la probabilité, et se prête davantage à des études à grande échelle.
Enfin, le procédé de localisation cellulaire étalon-or est immunomicroscopie. Cette technique utilise également un anticorps dirigé contre la protéine d'intérêt, ainsi que des techniques de microscopie électronique classique. L'échantillon est préparé pour examen au microscope électronique normal, puis traitée avec un anticorps dirigé contre la protéine d'intérêt qui est conjugué à un matériau extrêmement électro-dense, généralement en or. Cela permet la localisation des deux détails ultrastructuraux ainsi que la protéine d'intérêt.
Grâce à une autre application du génie génétique connue sous le nom mutagenèse dirigée, les chercheurs peuvent modifier la séquence de la protéine et par conséquent sa structure, localisation cellulaire, et la sensibilité à la réglementation. Cette même technique permet l'incorporation d'acides aminés non naturels dans des protéines, en utilisant des ARNt modifiés, et peut permettre à la conception rationnelle de nouvelles protéines avec des propriétés nouvelles.
Protéomique et bioinformatique
Le complément total de protéines présentes à la fois dans un type de cellule ou d'une cellule est connue comme son protéome, et l'étude de ces ensembles de données à grande échelle définit le domaine de la protéomique, nommés par analogie avec le domaine connexe de génomique. Techniques expérimentales en protéomique clés comprennent Électrophorèse 2D, ce qui permet la séparation d'un grand nombre de protéines, la spectrométrie de masse , ce qui permet l'identification à haut débit rapide des protéines et le séquençage de peptides (le plus souvent après dans le gel digestion), des puces à protéines, qui permettent la détection des niveaux relatifs d'un grand nombre de protéines présentes dans une cellule, et Double hybride, qui permet l'exploration systématique de interactions protéine-protéine. Le complément total de telles interactions possibles biologiquement est connu comme le interactome. Une tentative systématique de déterminer les structures de protéines représentant tous les plis possible est connu comme génomique structurale.
La grande quantité de données génomiques et protéomiques disponibles pour une variété d'organismes, y compris la génome humain, permet aux chercheurs d'identifier efficacement protéines homologues dans les organismes apparentés de loin par alignement de séquences . outils de profilage séquence peuvent effectuer des manipulations de séquences plus spécifiques tels que des cartes d'enzymes de restriction, analyses cadre de lecture ouvert pour des séquences nucléotidiques, et prédiction de la structure secondaire. De ces données, arbres phylogénétiques peuvent être construits et évolutifs hypothèses développées en utilisant un logiciel spécial comme ClustalW concernant l'ascendance des organismes modernes et les gènes qu'ils expriment. Le domaine de la bioinformatique cherche à assembler, annoter, et analyser les données génomiques et protéomiques, l'application de calcul des techniques à des problèmes biologiques tels que découverte de gènes et cladistics.
La prédiction des structures et de la simulation
Complémentaire dans le domaine de la génomique structurale, la prédiction de la structure des protéines cherche à développer des moyens efficaces pour fournir des modèles plausibles pour des protéines dont les structures ne ont pas encore été déterminée expérimentalement. Le type le plus réussi de prédiction de la structure, connue sous le nom modélisation d'homologie, se appuie sur l'existence d'une structure en "template" avec similarité de séquence avec la protéine en cours de modélisation; L'objectif de la génomique structurale est de fournir une représentation suffisante dans les structures résolus pour modéliser la plupart de ceux qui restent. Bien que la production de modèles précis reste un défi lorsque les structures de modèle qu'un lointain rapport sont disponibles, il a été suggéré que l'alignement de séquence est le goulot d'étranglement dans ce processus, comme des modèles très précis peuvent être produites si un alignement de séquences «parfait» est connu. De nombreuses méthodes de prédiction de la structure ont servi à informer le domaine émergent de la ingénierie des protéines, dans laquelle de nouveaux plis de protéines ont déjà été conçus. Un problème de calcul plus complexe est la prédiction d'interactions intermoléculaires, comme dans amarrage moléculaire et protéine-protéine de prédiction de l'interaction.
Les procédés de et le repliement des protéines de liaison peuvent être simulés à l'aide de ces techniques comme mécanique moléculaire, en particulier, la dynamique moléculaire et de Monte Carlo , qui prennent de plus en plus avantage de parallèle et l'informatique distribuée ( Folding @ Home projet; modélisation moléculaire sur GPU). Le pliage de petits domaines de protéines alpha-hélicoïdale comme le casque de la villine et VIH protéine accessoire ont été simulé avec succès in silico , et les méthodes hybrides qui combinent la dynamique moléculaire standard avec la mécanique quantique calculs ont permis d'exploration des états électroniques de rhodopsines.
Nutrition
Plus les micro-organismes et les plantes peuvent tous 20 types biosynthèse des acides aminés , tandis que les animaux (y compris humains) doivent obtenir certains des acides aminés de l' alimentation. Les acides aminés que l'organisme ne peut pas synthétiser de sa propre sont considérés comme des acides aminés essentiels. Enzymes clés qui synthétisent certains acides aminés ne sont pas présents chez les animaux - tels que l'aspartokinase, qui catalyse la première étape dans la synthèse de la lysine, la méthionine et la thréonine à partir de l'aspartate. Si acides aminés sont présents dans l'environnement, les microorganismes peuvent économiser de l'énergie en reprenant les acides aminés de leur environnement et de la régulation négative de leurs voies de biosynthèse.
Chez les animaux, les acides aminés sont obtenus par la consommation d'aliments contenant des protéines. Protéines ingérées sont ensuite décomposées en acides aminés à travers la digestion, ce qui implique généralement la dénaturation de la protéine par l'exposition à l'acide et l'hydrolyse par des enzymes appelées proteases. Certains acides aminés ingérés sont utilisés pour la biosynthèse des protéines, tandis que d'autres sont convertis en glucose par néoglucogenèse, ou introduits dans l' cycle de l'acide citrique. utilisation de la protéine Cet comme combustible est particulièrement important en vertu des conditions de famine, car il permet propres protéines de l'organisme à être utilisés pour soutenir la vie, en particulier ceux trouvés dans les musculaire. acides aminés sont également une importante source alimentaire de l'azote .
Histoire et étymologie
Les protéines ont été reconnus comme une catégorie distincte de molécules biologiques dans le XVIIIe siècle par Antoine Fourcroy et d'autres, qui se distingue par la capacité des molécules à coaguler ou floculer sous traitements avec de la chaleur ou de l'acide. Parmi les exemples cités à l'époque d'albumine, de blancs d'œufs, le sang , le sérum albumine fibrine, et le blé gluten. Chimiste hollandais Gerhardus Johannes Mulder effectués analyse élémentaire des protéines communes et a constaté que presque toutes les protéines ont la même formule empirique, C 400 H 620 N 100 O 120 P 1 S 1 . Il est venu à la conclusion erronée qu'ils pourraient être composés d'un seul type de (très grande) molécule. Le terme «protéine» pour décrire ces molécules a été proposé en 1838 par l'associé de Mulder Jöns Jakob Berzelius; protéine est dérivée du grec mot πρωτεῖος ( proteios ), ce qui signifie "primaire", "dans la tête", ou "debout devant". Mulder a continué à identifier les produits de dégradation des protéines telles que l' acide aminé leucine pour lequel il a trouvé un (presque correct) poids moléculaire de 131 Da.
La difficulté dans la purification de protéines en grandes quantités les rendait très difficile pour les premiers biochimistes de protéines pour étudier. Par conséquent, les premières études ont porté sur les protéines qui pourraient être purifiés en grandes quantités, par exemple, ceux de sang , blanc d'oeuf, diverses toxines, et digestifs / enzymes métaboliques obtenus à partir des abattoirs. Dans les années 1950, l' Armour Hot Dog Co. purifié 1 kg de pur pancréatique bovine ribonucléase A et fait librement disponible pour les scientifiques; ce geste a aidé ribonucléase A devenir une cible majeure pour l'étude biochimique pour les décennies suivantes.
Linus Pauling est crédité de la prédiction réussie de protéines réguliers structures secondaires basées sur la liaison hydrogène, une idée la première fois par William Astbury en 1933. travail plus tard par Walter Kauzmann sur la dénaturation, basée en partie sur des études antérieures par Kaj Linderstrøm-Lang, a contribué d'une compréhension de repliement des protéines et de la structure à médiation par des interactions hydrophobes. En 1949 Fred Sanger correctement déterminé la séquence d'acides aminés de l'insuline , ce qui démontre de façon concluante que les protéines étaient composés de polymères linéaires d'acides aminés plutôt que des chaînes ramifiées, des colloïdes ou des cyclols. Les premières structures à résolution atomique de protéines ont été résolues par cristallographie aux rayons X dans les années 1960 et par RMN dans les années 1980. En 2009, le Protein Data Bank a plus de 55 000 structures à résolution atomique de protéines. Dans des temps plus récents, cryo-microscopie électronique de grands assemblages macromoléculaires et de calcul de prédiction de la structure des protéines de petites protéines domaines sont deux méthodes approchant résolution atomique.